HDFS学习记录(数据单位的比较、读写流程)
- 作者: 李二驴
- 来源: 51数据库
- 2021-09-19
1. HDFS的整体架构
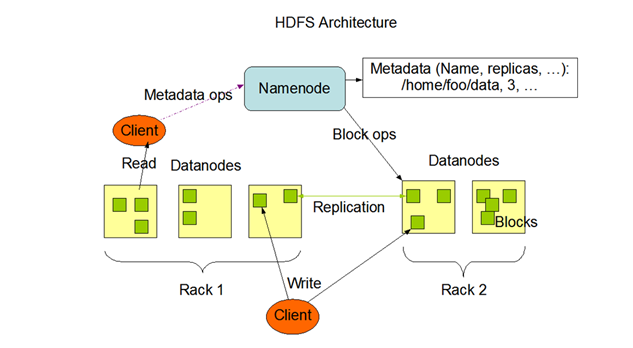
- 模糊词汇解释:
Client:凡是通过API或者HDFS命令访问HDFS的一端,都可以看做是客户。Rack:机架,副本的放置策略与机架有关。Block Size:Hadoop2.7.3开始默认为128 M,Hadoop2.7.3以下默认为64 M。
2. block、packet、chunk的关系
- block、packet、chunk都是HDFS中涉及到的数据存储单位。
- Hadoop中我们自己可以配置的xml文件:
core-site.xml、hdfs-site.xml等,当不知道如何进行修改时,可以查看core-default.xml、hdfs-site.xml等文件。
① block
- block是HDFS中文件分块的单位,一个文件没有64 M也会占据一个block,size是文件的实际大小,blocksize是块的大小。
- 可以在
hdfs-site.xml文件中,通过dfs.block.size配置项修改默认的块大小。 - block与磁盘寻址时间、传输时间的关系:
- block越大,磁盘寻址时间越短,数据传输时间越长。
- block越小,磁盘寻址时间越长,数据传输时间越短。
- block设置过小:
- NameNode内存过载: 如果block设置过小,
NameNode内存中存储大量小文件的元数据信息,会导致NameNode内存过载。 - 寻址时间过长: 如果block设置过小,磁盘寻址时间增大,使得程序一直在查找block的开始位置。
- block设置过大:
- Map任务时间过长:
MapReduce中Map通常一次只处理一个数据块中的任务,如果block设置过大,将会导致Map任务的处理时间过长。 - 数据传输时间过长: 如果block设置过大,数据传输时间远超数据寻址时间,影响数据的处理速度。
② packet
- packet是第二大的单位,它是DFSClient向DataNode,或DataNode的Pipeline之间数据传输的基本单位,默认大小为64 kb。
- 可以在
hdfs-site.xml文件中,通过dfs.write.packet.size配置项修改默认的packet大小。
③ chunk
- chunk是最小的单位,它
DFSClient向DataNode,或DataNode的Pipeline之间进行数据校验的基本单位,默认为512 byte。 - 可以在
core-site.xml文件中,通过io.bytes.per.checksum配置项修改默认的chunk大小。 - chunk作为数据校验的基本单位,每个chunk需要携带4 byte的校验信息。因此,实际写入到packet时为516 byte,真实数据与校验数据的比值为
128 : 1。 - 举例: 一个128M的文件,可以划分为256个chunk,共需要携带
256 * 4 byte = 1 M的校验信息。 - 三者的总结:
- chunk是
DFSClient向DataNode或DataNode的Pipeline之间进行数据校验的基本单位,每个chunk需要携带4 byte的校验信息。 - packet是
DFSClient向DataNode或DataNode的Pipeline之间进行数据传输的基本单位,chunk向packet中写入时的实际大小为516 byte。 - block是文件分块的单位,无数个packet构成一个block。小文件不足一个block大小,但会占据一个元数据的slot,导致
NameNode内存过载。
④ 写过程中的三层buffer
- 写过程会涉及到chunk、packet、
DataQueue三个粒度的三层缓存:
- 数据流入
DFSOutputStream时,其中会有一个chunk大小的buffer。当数据写满这个buffer,或遇到强制的flush()操作时,会计算校验和(checksum)。 - 将chunk和校验和一起写入packet中,当多个chunk将packet填满后,这个packet会进入
DataQueue队列。 DataQueue中的packet被线程取出并发送到DataNode中,未确认写入成功的packet将会移动到AckQueue中等待确认。- 如果接收到
DataNode的ack(写入成功),则由ResponseProcessor负责将packet从AckQueue中删除;否则,将会移动到DataQueue中,重新写入。
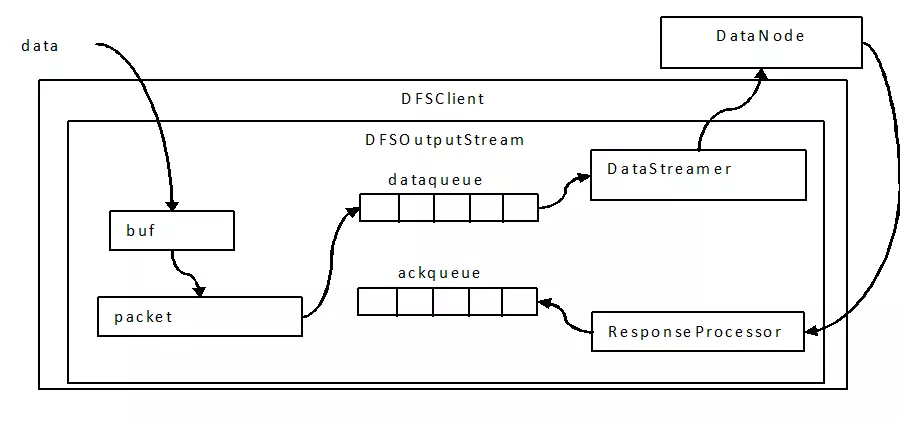
三层buffer
3. 基础知识
NameNode
- 管理元数据信息(Metadata),注意,只存储元数据信息。
- namenode对于元数据信息的管理,放在内存一份,供访问查询,也会通过fsimage和edits文件,将元数据信息持久化到磁盘上。
- Hadoop1.0版本利用了SecondaryNamenode做fsimage和edits文件的合并,但是这种机制达不到热备的效果。Hadoop1.0的namenode存在单点故障问题。
- 元数据大致分成两个层次:Namespace管理层,负责管理文件系统中的树状目录结构以及文件与数据块的映射关系。块管理层,负责管理文件系统中文件的物理块与实际存储位置的映射关系BlocksMap。
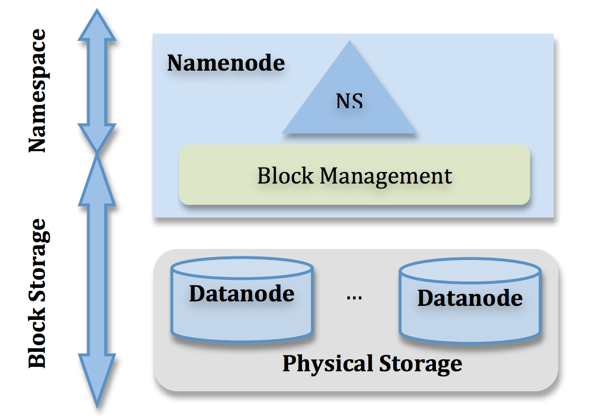
datanode
- 数据节点,用于存储文件块。
- 为了防止datanode挂掉造成的数据丢失,对于文件块要有备份,一个文件块默认三个副本。
rack
- 机架,HDFS使用机架感知(rack awareness)策略来放置副本。
- 第一个副本:如果writer就是一个dataNode,则直接放在本地;否则,随机选择一个dataNode进行存储。
- 第二个副本:远程机架上的某个dataNode
- 第三个副本:与第二个副本相同的远程机架上的另一个dataNode。
- 这样的放置策略,减少了机架间的写流量,提高了写性能。
- 超过3个副本:其余副本的放置要求满足以下条件:
- 一个dataNode只允许拥有block的一个副本
- Hadoop集群的最大副本数为dataNode的总数
参考链接:HDFS之Replica Placement Policy
client
- 客户端,凡是通过API或指令操作的一端都可以看做是客户端
blockSize
- 数据块,一般有默认大小,可以通过hdfs-site.xml文件中的
dfs.blocksize进行配置。 - Hadoop1.0:64MB。Hadoop2.0 :128MB。
- 块大小的问题:从大数据处理角度来看,块越大越好。所以从技术的发展,以后的块会越来越大,因为块大,会减少磁盘寻址次数,从而减少寻址时间.
4. HDFS的读写流程
① HDFS的读流程
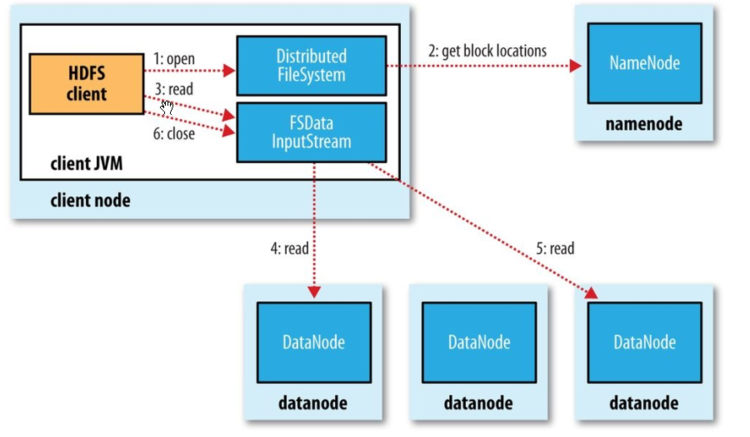
- client调用DistributedFileSystem.open( ) 方法,获得要读取数据块的输入流对象(FSDataInputStream)。
- open()方法运行时,DistributedFileSystem使用 RPC 方式调用NameNode,从而获得block所有副本的dataNode地址。open()方法运行结束后,返回FSDataInputStream对象,该对象封装了输入流 DFSInputStream。
- 调用输入流 FSDataInputStream.read( ) 方法,从而让DFSInputStream按照就近原则自动连接到适合的dataNode进行数据读取(网络拓扑的远近)。
- 循环调用 read( ) 方法,从而将数据从 dataNode 传输到客户端。
- 当前块读取完毕,关闭与当前dataNode的连接。建立与下一个块的dataNode的连接,从而继续读取下一个块。
这个过程对客户端来说是透明的,在客户端那边看来,就像是只读取了一个连续不断的流。
- 客户端读取完所有的块,调用 FSDataInputStream.close( )关闭输入流,从而结束此次文件读取流程。
- 读取错误:
- 在读取过程中出错,DFSInputStream会尝试读取临近DataNode中的block。同时也会记录下出问题的dataNode,在之后的数据请求过程中不再与之通信。
- 每次读完一个block,DFSInputStream都会检验数据的完整性。如果有损坏,客户端会通知NameNode,并继续从其它DataNode读取副本。
② HDFS的写流程
- client调用分布式文件系统
DistributedFileSystem.create( )方法,向NameNode发送创建文件请求。 - create()方法运行时,
DistributedFileSystem向NameNode发送RPC请求,有NameNode完成文件创建前的检查工作。如果通过检查,首先在EditLog中记录写操作,然后返回输出流对象FSDataOutputStream(内部封装了DFSOutputDtream)。 - 客户端调用
FSOutputStream.write()函数,向对应的文件写入数据。 - 写入文件时,
DFSOutputDtream会将文件分成一个个的packet,并将packet写入DataQueue中。DataStreamer负责管理DataQueue,它会要求 NameNode 分配适合的新块用于存储副本。DataNode之间形成pipeline,packet通过pipeline进行传输。
-
DataStreamer将packet通过pipeline流式传输到DataNode1 - DataNode1将收到的packet传送给DataNode2
- DataNode2将收到的packet传送给DataNode3,从而形成packet的三副本存储。
- 为了保证副本的一致性,接收到packet的DataNode完成需要向发送者返回ack packet。收到足够的应答后,packet将会从内部队列中删除。
- 完成文件写入后,客户端调用
FSOutputStream.close()方法,关闭文件输入流。 - 调用
DistributedFileSystem.complete()方法,通知NameNode文件写入成功。
推荐阅读