Go微服务全链路跟踪详解
- 作者: 联合国抬杠队秘书长
- 来源: 51数据库
- 2021-09-21
在微服务架构中,调用链是漫长而复杂的,要了解其中的每个环节及其性能,你需要全链路跟踪。 它的原理很简单,你可以在每个请求开始时生成一个唯一的id,并将其传递到整个调用链。 该id称为correlationid1,你可以用它来跟踪整个请求并获得各个调用环节的性能指标。简单来说有两个问题需要解决。第一,如何在应用程序内部传递id; 第二,当你需要调用另一个微服务时,如何通过网络传递id。
什么是opentracing?
现在有许多开源的分布式跟踪库可供选择,其中最受欢迎的库可能是zipkin2和jaeger3。 选择哪个是一个令人头疼的问题,因为你现在可以选择最受欢迎的一个,但是如果以后有一个更好的出现呢?opentracing?可以帮你解决这个问题。它建立了一套跟踪库的通用接口,这样你的程序只需要调用这些接口而不被具体的跟踪库绑定,将来可以切换到不同的跟踪库而无需更改代码。zipkin和jaeger都支持opentracing。
如何跟踪服务器端点(server endpoints)?
在下面的程序中我使用“zipkin”作为跟踪库,用“opentracing”作为通用跟踪接口。 跟踪系统中通常有四个组件,下面我用zipkin作为示例:
recorder(记录器):记录跟踪数据
reporter (or collecting agent)(报告器或收集代理):从记录器收集数据并将数据发送到ui程序
tracer:生成跟踪数据
ui:负责在图形ui中显示跟踪数据
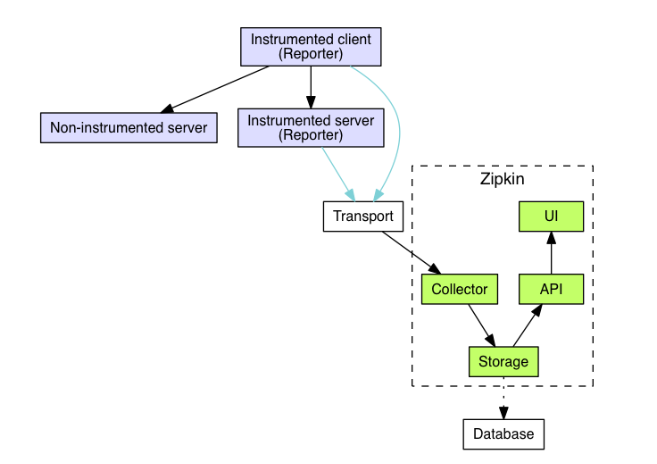
上面是zipkin的组件图,你可以在zipkin architecture中找到它。
有两种不同类型的跟踪,一种是进程内跟踪(in-process),另一种是跨进程跟踪(cross-process)。 我们将首先讨论跨进程跟踪。
客户端程序:
我们将用一个简单的grpc程序作为示例,它分成客户端和服务器端代码。 我们想跟踪一个完整的服务请求,它从客户端到服务端并从服务端返回。 以下是在客户端创建新跟踪器的代码。它首先创建“http collector”(the agent)用来收集跟踪数据并将其发送到“zipkin” ui, “endpointurl”是“zipkin” ui的url。 其次,它创建了一个记录器(recorder)来记录端点上的信息,“hosturl”是grpc(客户端)呼叫的url。第三,它用我们新建的记录器创建了一个新的跟踪器(tracer)。 最后,它为“opentracing”设置了“globaltracer”,这样你可以在程序中的任何地方访问它。
const (
endpoint_url = "http://localhost:9411/api/v1/spans"
host_url = "localhost:5051"
service_name_cache_client = "cache service client"
service_name_call_get = "callget"
)
func newtracer () (opentracing.tracer, zipkintracer.collector, error) {
collector, err := openzipkin.newhttpcollector(endpoint_url)
if err != nil {
return nil, nil, err
}
recorder :=openzipkin.newrecorder(collector, true, host_url, service_name_cache_client)
tracer, err := openzipkin.newtracer(
recorder,
openzipkin.clientserversamespan(true))
if err != nil {
return nil,nil,err
}
opentracing.setglobaltracer(tracer)
return tracer,collector, nil
}
以下是grpc客户端代码。 它首先调用上面提到的函数“newtrace()”来创建跟踪器,然后,它创建一个包含跟踪器的grpc调用连接。接下来,它使用新建的grpc连接创建缓存服务(cache service)的grpc客户端。 最后,它通过grpc客户端来调用缓存服务的“get”函数。
key:="123"
tracer, collector, err :=newtracer()
if err != nil {
panic(err)
}
defer collector.close()
connection, err := grpc.dial(host_url,
grpc.withinsecure(), grpc.withunaryinterceptor(otgrpc.opentracingclientinterceptor(tracer, otgrpc.logpayloads())),
)
if err != nil {
panic(err)
}
defer connection.close()
client := pb.newcacheserviceclient(connection)
value, err := callget(key, client)
trace 和 span:
在opentracing中,一个重要的概念是“trace”,它表示从头到尾的一个请求的调用链,它的标识符是“traceid”。 一个“trace”包含有许多跨度(span),每个跨度捕获调用链内的一个工作单元,并由“spanid”标识。 每个跨度具有一个父跨度,并且一个“trace”的所有跨度形成有向无环图(dag)。 以下是跨度之间的关系图。 你可以从the opentracing semantic specification中找到它。

以下是函数“callget”的代码,它调用了grpc服务端的“get"函数。 在函数的开头,opentracing为这个函数调用开启了一个新的span,整个函数结束后,它也结束了这个span。
const service_name_call_get = "callget"
func callget(key string, c pb.cacheserviceclient) ( []byte, error) {
span := opentracing.startspan(service_name_call_get)
defer span.finish()
time.sleep(5*time.millisecond)
// put root span in context so it will be used in our calls to the client.
ctx := opentracing.contextwithspan(context.background(), span)
//ctx := context.background()
getreq:=&pb.getreq{key:key}
getresp, err :=c.get(ctx, getreq )
value := getresp.value
return value, err
}
服务端代码:
下面是服务端代码,它与客户端代码类似,它调用了“newtracer()”(与客户端“newtracer()”函数几乎相同)来创建跟踪器。然后,它创建了一个“opentracingserverinterceptor”,其中包含跟踪器。 最后,它使用我们刚创建的拦截器(interceptor)创建了grpc服务器。
connection, err := net.listen(network, host_url)
if err != nil {
panic(err)
}
tracer,err := newtracer()
if err != nil {
panic(err)
}
opts := []grpc.serveroption{
grpc.unaryinterceptor(
otgrpc.opentracingserverinterceptor(tracer,otgrpc.logpayloads()),
),
}
srv := grpc.newserver(opts...)
cs := initcache()
pb.registercacheserviceserver(srv, cs)
err = srv.serve(connection)
if err != nil {
panic(err)
} else {
fmt.println("server listening on port 5051")
}
以下是运行上述代码后在zipkin中看到的跟踪和跨度的图片。 在服务器端,我们不需要在函数内部编写任何代码来生成span,我们需要做的就是创建跟踪器(tracer),服务器拦截器自动为我们生成span。
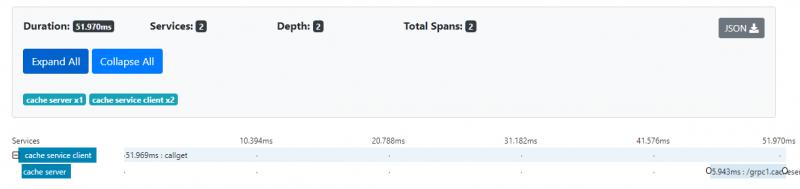
怎样跟踪函数内部?
上面的图片没有告诉我们函数内部的跟踪细节, 我们需要编写一些代码来获得它。
以下是服务器端“get”函数,我们在其中添加了跟踪代码。 它首先从上下文获取跨度(span),然后创建一个新的子跨度并使用我们刚刚获得的跨度作为父跨度。 接下来,它执行一些操作(例如数据库查询),然后结束(mysqlspan.finish())子跨度。
const service_name_db_query_user = "db query user"
func (c *cacheservice) get(ctx context.context, req *pb.getreq) (*pb.getresp, error) {
time.sleep(5*time.millisecond)
if parent := opentracing.spanfromcontext(ctx); parent != nil {
pctx := parent.context()
if tracer := opentracing.globaltracer(); tracer != nil {
mysqlspan := tracer.startspan(service_name_db_query_user, opentracing.childof(pctx))
defer mysqlspan.finish()
//do some operations
time.sleep(time.millisecond * 10)
}
}
key := req.getkey()
value := c.storage[key]
fmt.println("get called with return of value: ", value)
resp := &pb.getresp{value: value}
return resp, nil
}
以下是它运行后的图片。 现在它在服务器端有一个新的跨度“db query user”。
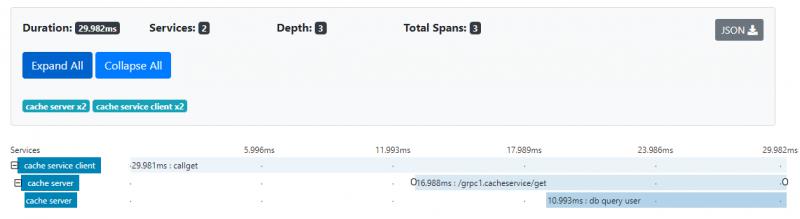
以下是zipkin中的跟踪数据。 你可以看到客户端从8.016ms开始,服务端也在同一时间启动。 服务器端完成需要大约16ms。
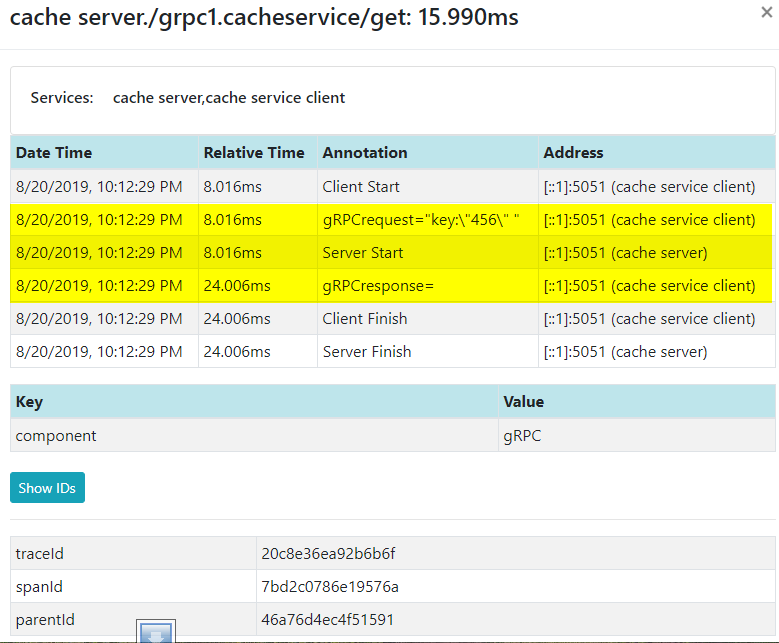
怎样跟踪数据库?
怎样才能跟踪数据库内部的操作?首先,数据库驱动程序需要支持跟踪,另外你需要将跟踪器(tracer)传递到数据库函数中。如果数据库驱动程序不支持跟踪怎么办?现在已经有几个开源驱动程序封装器(wrapper),它们可以封装任何数据库驱动程序并使其支持跟踪。其中一个是instrumentedsql?(另外两个是?和?)。我简要地看了一下他们的代码,他们的原理基本相同。它们都为底层数据库的每个函数创建了一个封装(wrapper),并在每个数据库操作之前启动一个新的跨度,并在操作完成后结束跨度。但是所有这些都只封装了“database/sql”接口,这就意味着nosql数据库没有办法使用他们。如果你找不到支持你需要的nosql数据库(例如mongodb)的opentracing的驱动程序,你可能需要自己编写一个封装(wrapper),它并不困难。
一个问题是“如果我使用opentracing和zipkin而数据库驱动程序使用openeracing和jaeger,那会有问题吗?"这其实不会发生。我上面提到的大部分封装都支持opentracing。在使用封装时,你需要注册封装了的sql驱动程序,其中包含跟踪器。在sql驱动程序内部,所有跟踪函数都只调用了opentracing的接口,因此它们甚至不知道底层实现是zipkin还是jaeger。现在使用opentarcing的好处终于体现出来了。在应用程序中创建全局跟踪器时(global tracer),你需要决定是使用zipkin还是jaeger,但这之后,应用程序或第三方库中的每个函数都只调用opentracing接口,已经与具体的跟踪库(zipkin或jaeger)没关系了。
怎样跟踪服务调用?
假设我们需要在grpc服务中调用另外一个微服务(例如restful服务),该如何跟踪?
简单来说就是使用http头作为媒介(carrier)来传递跟踪信息(traceid)。无论微服务是grpc还是restful,它们都使用http协议。如果是消息队列(message queue),则将跟踪信息(traceid)放入消息报头中。(zipkin b3-propogation有“single header”和“multiple header”有两种不同类型的跟踪信息,但jms仅支持“single header”)
一个重要的概念是“跟踪上下文(trace context)”,它定义了传播跟踪所需的所有信息,例如traceid,parentid(父spanid)等。有关详细信息,请阅读跟踪上下文(trace context)1?。
opentracing提供了两个处理“跟踪上下文(trace context)”的函数:“extract(format,carrier)”和“inject(spancontext,format,carrier)”。 “extarct()”从媒介(通常是http头)获取跟踪上下文。 “inject”将跟踪上下文放入媒介,来保证跟踪链的连续性。以下是我从zipkin获取的图。
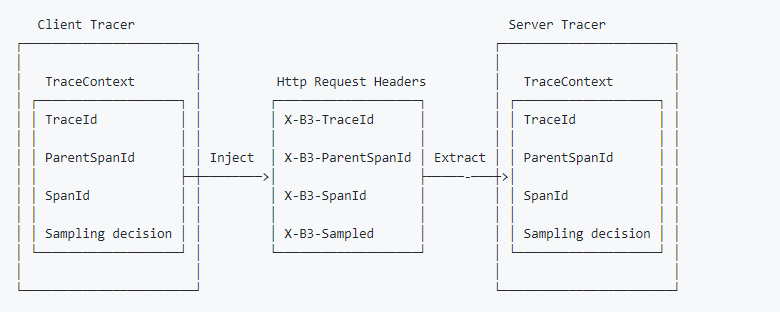
但是为什么我们没有在上面的例子中调用这些函数呢?让我们再来回顾一下代码。在客户端,在创建grpc客户端连接时,我们调用了一个为“opentracingclientinterceptor”的函数。 以下是“opentracingclientinterceptor”的部分代码,我从11包中的“client.go”中得到了它。它已经从go context12获取了跟踪上下文并将其注入http头,因此我们不再需要再次调用“inject”函数。
func opentracingclientinterceptor(tracer opentracing.tracer, optfuncs ...option)
grpc.unaryclientinterceptor {
...
ctx = injectspancontext(ctx, tracer, clientspan)
...
}
func injectspancontext(ctx context.context, tracer opentracing.tracer, clientspan opentracing.span)
context.context {
md, ok := metadata.fromoutgoingcontext(ctx)
if !ok {
md = metadata.new(nil)
} else {
md = md.copy()
}
mdwriter := metadatareaderwriter{md}
err := tracer.inject(clientspan.context(), opentracing.httpheaders, mdwriter)
// we have no better place to record an error than the span itself :-/
if err != nil {
clientspan.logfields(log.string("event", "tracer.inject() failed"), log.error(err))
}
return metadata.newoutgoingcontext(ctx, md)
}
在服务器端,我们还调用了一个函数“otgrpc.opentracingserverinterceptor”,其代码类似于客户端的“opentracingclientinterceptor”。它不是调用“inject”写入跟踪上下文,而是从http头中提取(extract)跟踪上下文并将其放入go上下文(go context)中。 这就是我们不需要再次手动调用“extract()”的原因。 我们可以直接从go上下文中提取跟踪上下文(opentracing.spanfromcontext(ctx))。 但对于其他基于http的服务(如restful服务), 情况就并非如此,因此我们需要写代码从服务器端的http头中提取跟踪上下文。 当然,您也可以使用拦截器或过滤器。
跟踪库之间的互兼容性
你也许会问“如果我的程序使用zipkin和opentracing而需要调用的第三方微服务使用opentracing与jaeger,它们会兼容吗?"它看起来于我们之前询问的数据库问题类似,但实际上很不相同。对于数据库,因为应用程序和数据库在同一个进程中,它们可以共享相同的全局跟踪器,因此更容易解决。对于微服务,这种方式将不兼容。因为opentracing只标准化了跟踪接口,它没有标准化跟踪上下文。万维网联盟(w3c)正在制定1?的标准,并于2019-08-09年发布了候选推荐标准。opentracing没有规定跟踪上下文的格式,而是把决定权留给了实现它的跟踪库。结果每个库都选择了自己独有的的格式。例如,zipkin使用“x-b3-traceid”作为跟踪id,jaeger使用“uber-trace-id”,因此使用opentracing并不意味着不同的跟踪库可以进行跨网互操作。 对于“jaeger”来说有一个好处是你可以选择使用“zipkin兼容性功能"13来生成zipkin跟踪上下文, 这样就可以与zipkin相互兼容了。对于其他情况,你需要自己进行手动格式转换(在“inject”和“extract”之间)。
全链路跟踪设计
尽量少写代码
一个好的全链路跟踪系统不需要用户编写很多跟踪代码。最理想的情况是你不需要任何代码,让框架或库负责处理它,当然这比较困难。 全链路跟踪分成三个跟踪级别:
跨进程跟踪 (cross-process)(调用另一个微服务)
数据库跟踪
进程内部的跟踪 (in-process)(在一个函数内部的跟踪)
跨进程跟踪是最简单的。你可以编写拦截器或过滤器来跟踪每个请求,它只需要编写极少的编码。数据库跟踪也比较简单。如果使用我们上面讨论过的封装器(wrapper),你只需要注册sql驱动程序封装器(wrapper)并将go-context(里面有跟踪上下文) 传入数据库函数。你可以使用依赖注入(dependency injection)这样就可以用比较少的代码来完成此操作。
进程内跟踪是最困难的,因为你必须为每个单独的函数编写跟踪代码。现在还没有一个很好的方法,可以编写一个通用的函数来跟踪应用程序中的每个函数(拦截器不是一个好选择,因为它需要每个函数的参数和返回都必须是一个泛型类型(interface {}))。幸运的是,对于大多数人来说,前两个级别的跟踪应该已经足够了。
有些人可能会使用服务网格(service mesh)来实现分布式跟踪,例如istio或linkerd。它确实是一个好主意,跟踪最好由基础架构实现,而不是将业务逻辑代码与跟踪代码混在一起,不过你将遇到我们刚才谈到的同样问题。服务网格只负责跨进程跟踪,函数内部或数据库跟踪任然需要你来编写代码。不过一些服务网格可以通过提供与流行跟踪库的集成,来简化不同跟踪库跨网跟踪时的的上下文格式转换。
跟踪设计:
精心设计的跨度(span),服务名称(service name),标签(tag)能充分发挥全链路跟踪的作用,并使之简单易用。有关信息请阅读语义约定(semantic conventions)1?。
将trace id记录到日志
将跟踪与日志记录集成是一个常见的需求,最重要的是将跟踪id记录到整个调用链的日志消息中。 目前opentracing不提供访问traceid的方法。 你可以将“opentracing.spancontext”转换为特定跟踪库的“spancontext”(zipkin和jaeger都可以通过“spancontext”访问traceid)或将“opentracing.spancontext”转换为字符串并解析它以获取traceid。转换为字符串更好,因为它不会破坏程序的依赖关系。 幸运的是不久的将来你就不需要它了,因为opentracing将提供访问traceid的方法,请阅读。
opentracing 和 opencensus
opencensus1?不是另一个通用跟踪接口,它是一组库,可以用来与其他跟踪库集成以完成跟踪功能,因此它经常与opentracing进行比较。 那么它与opentracing兼容吗?答案是否定的。 因此,在选择跟踪接口时(不论是opentracing还是opencensus)需要小心,以确保你需要调用的其他库支持它。 一个好消息是,你不需要在将来做出选择,因为它们会1?。
结论:
全链路跟踪包括不同的场景,例如在函数内部跟踪,数据库跟踪和跨进程跟踪。 每个场景都有不同的问题和解决方案。如果你想设计更好的跟踪解决方案或为你的应用选择最适合的跟踪工具或库,那你需要对每种情况都有清晰的了解。
源码:
索引:
[1]correlation ids for microservices architectures
[2]zipkin
[3]jaeger: open source, end-to-end distributed tracing
[4]opentracing
[5]zipkin architecture
[6]the opentracing semantic specification
[7]instrumentedsql
https://github.com/expansiveworlds/instrumentedsql
[8]luna-duclos/instrumentedsql
[9]ocsql/driver.go
[10]trace context
https://www.w3.org/tr/trace-context/
[11]otgrpc
[12]go concurrency patterns: context
[13]zipkin compatibility features
[14]semantic conventions
[15]opencensus
[16]merge the project into one

