Java GBK 中文乱码问题分析
- 作者: 清馨10456190
- 来源: 51数据库
- 2020-08-18
在io相关的操作中经常会出现乱码问题
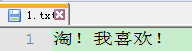
比如在一个txt文件中按GBK编码保存内容”淘!我喜欢!”
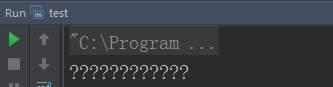
然后用RandomAccessFile类读取并打印一行。
RandomAccessFile raf = new RandomAccessFile("D://1.txt","r");
System.out.print(raf.readLine());
打印结果显示乱码:
在网上查询到加入相关编码解码操作后可以解决该问题
RandomAccessFile raf = new RandomAccessFile("D://1.txt","r");
System.out.print(new String(raf.readLine().getBytes("ISO-8859-1"),"gbk"));
问题:
在这个过程中发生了什么?
要解答这个问题首先要知道编码和解码的概念以及产生的原因:
为什么要编码
不知道大家有没有想过一个问题,那就是为什么要编码?我们能不能不编码?要回答这个问题必须要回到计算机是如何表示我们人类能够理解的符号的,这些符号也就是我们人类使用的语言。由于人类的语言有太多,因而表示这些语言的符号太多,无法用计算机中一个基本的存储单元—— byte 来表示,因而必须要经过拆分或一些翻译工作,才能让计算机能理解。我们可以把计算机能够理解的语言假定为英语,其它语言要能够在计算机中使用必须经过一次 翻译,把它翻译成英语。这个翻译的过程就是编码。所以可以想象只要不是说英语的国家要能够使用计算机就必须要经过编码。这看起来有些霸道,但是这就是现 状,这也和我们国家现在在大力推广汉语一样,希望其它国家都会说汉语,以后其它的语言都翻译成汉语,我们可以把计算机中存储信息的最小单位改成汉字,这样 我们就不存在编码问题了。
所以总的来说,编码的原因可以总结为:
1. 计算机中存储信息的最小单元是一个字节即 8 个 bit,所以能表示的字符范围是 0~255 个。
2. 人类要表示的符号太多,无法用一个字节来完全表示。
3. 要解决这个矛盾必须需要一个新的数据结构 char,从 char 到 byte 必须编码。
名词解释:
解码:将byte数组转为char数组。
编码:将char数组转为byte数组。
计算机存储的基本单位是byte,但打开一个文件时文件编辑器已经做了解码的工作。
以下为解码过程描述
文件实际存储的内容是(以下为 16 进制):
打开文件后看到的内容为
需要详细说明以下代码的处理过程
RandomAccessFile raf= new RandomAccessFile("D://1.txt","r");
System.out.print(raf.readLine());
首先看一下java.io.RandomAccessFile#readLine方法的源码
public final String readLine() throws IOException {
StringBuffer input = new StringBuffer();
int c = -1;
boolean eol = false;
while (!eol) {
switch (c = read()) {
case -1:
case '/n':
eol = true;
break;
case '/r':
eol = true;
long cur = getFilePointer();
if ((read()) != '/n') {
seek(cur);
}
break;
default:
input.append((char)c);
break;
}
}
if ((c == -1) && (input.length() == 0)) {
return null;
}
return input.toString();
}
主要关注read()部分和(char)c,read()是一个本地方法,作用是从文件中读取一个byte字节。

(char)c是将变量c从byte类型转换为char类型,这是一个解码操作。
问题:此处是以什么格式进行解码?
解码格式是ISO-8859-1
raf.readLine()的处理过程如下
那么
new String(raf.readLine().getBytes("ISO-8859-1"),"gbk")
这行代码做了什么
首先readLine()按行一字节一字节地读取文件中的数据,并且按ISO-8859-1进行解码拼成char数组,然后getBytes(“ISO-8859-1″)对拼成后的char数组按ISO-8859-1进行编码获取byte数组,最后new String(string,”gbk”)对编码后的byte数组用gbk格式进行解码成char数组。
参考资料: 深入分析 Java 中的中文编码问题
遗留问题:
1 、如何避免重复转码。
2 、RandomAccessFile的readLine () 效率非常低,如何提高效率。

