批处理处理文本文件去重复实现代码
- 作者: BETTER62881837
- 来源: 51数据库
- 2021-08-14
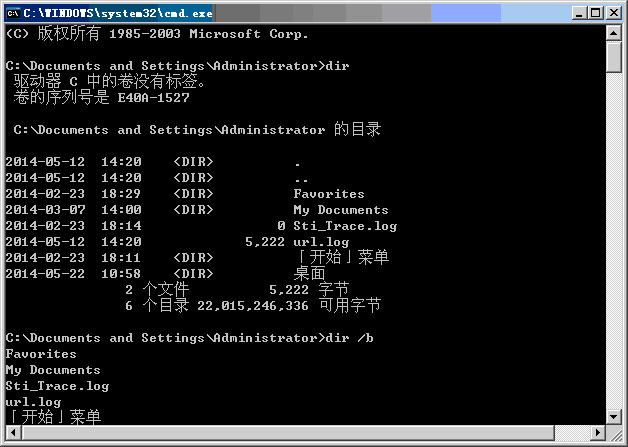
最近需要将重复的内容去掉,所以就想到了使用bat或vbs实现,没想到网上已经有人写好了,测试也正好学习一下
使用方法:把文本拖到批处理上就行了。。。
@echo off
:: code by oicu#lsxk.org 2007/11/29
rem chcp 437>nul
:: 看情况使用,utf-8编码的文件不能少了chcp命令,一般无需使用,
:: 但无论是否使用都不支持utf-16的文件。
:: pushd "%~dp1"
:: 如果不用pushd和popd,文件都要用绝对路径不能只用文件名。
if "%~1"=="" goto :eof
set outputfile=%~dpn1_output%~x1
type nul>"%outputfile%"
echo waiting...
for /f "tokens=1* delims=:" %%i in ('findstr /n .* "%~1"') do (
findstr /b /e /c:"%%j" "%outputfile%">nul 2>&1 || echo.%%j>>"%outputfile%"
)
pause
start "" notepad "%outputfile%"
:: popd
exit
【 在 oicu (oh! i see you!) 的大作中提到: 】
: 去重复倒是行。。缺点就是慢和保留原有的空行了。
以下是vbs实现的代码
以下是这个脚本的源代码,复制后另存为vbs后缀的文件,双击即可运行。文件要放在c盘根下的text.txt,请特别注意:文本中一行一条记录,不要有空行。
const adopenstatic = 3
const adlockoptimistic = 3
const adcmdtext = &h0001
set objconnection = createobject("adodb.connection")
set objrecordset = createobject("adodb.recordset")
strpathtotextfile = "c:"
strfile = "test.txt"
objconnection.open "provider=microsoft.jet.oledb.4.0;" & _
"data source=" & strpathtotextfile & ";" & _
"extended properties=""text;hdr=no;fmt=delimited"""
objrecordset.open "select distinct * from " & strfile, _
objconnection, adopenstatic, adlockoptimistic, adcmdtext
do until objrecordset.eof
set objfso = createobject("scripting.filesystemobject")
set fp=objfso.opentextfile("c:\test1.txt",8,true,0)
fp.writeline objrecordset.fields.item(0).value
fp.close
set objfso = nothing
objrecordset.movenext
loop
推荐阅读