2020李宏毅学习笔记——48.More about Auto-Encoder(2_4)
- 作者: ADAMSIR
- 来源: 51数据库
- 2021-10-02
Sequential Data
除了图像数据外,我们也可以在序列数据上使用Encoder-Decoder的结构模型。
1.Skip thought
模型在大量的文档数据上训练结束后,Encoder接收一个句子,然后给出输入句子的上一句和下一句是什么。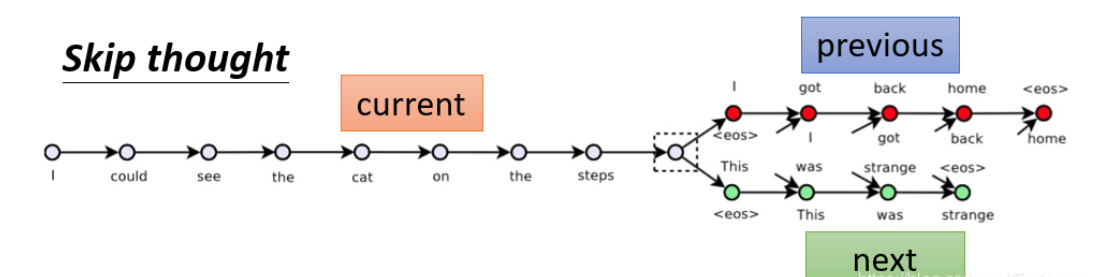
这个模型训练过程和训练word embedding很像,因为训练word embedding的时候有这么一个原则,就是两个词的上下文很像的时候,这两个词的embedding就会很接近。换到句子的模型上,如果两个句子的上下文很像,那么这两个句子的embedding就应该很接近。
例如:
这个东西多少钱?答:10元。
这个东西多贵?答:10元。
发现答案一样,所以问句的embedding是很接近的。
2.Quick thought
而Quick thought是对于Skip thought的改进版本,它不使用Decoder,而是使用一个辅助的分类器。它将当前的句子、当前句子的下一句和一些随机采样得到的句子分别送到Encoder中得到对应的Embedding,然后将它们丢给分类器。因为当前的句子的Embedding和它下一句的Embedding应该是越接近越好,而它和随机采样句子的Embedding应该差别越大越好,因此分类器应该可以根据Embedding判断出哪一个代表的是当前句子的下一句。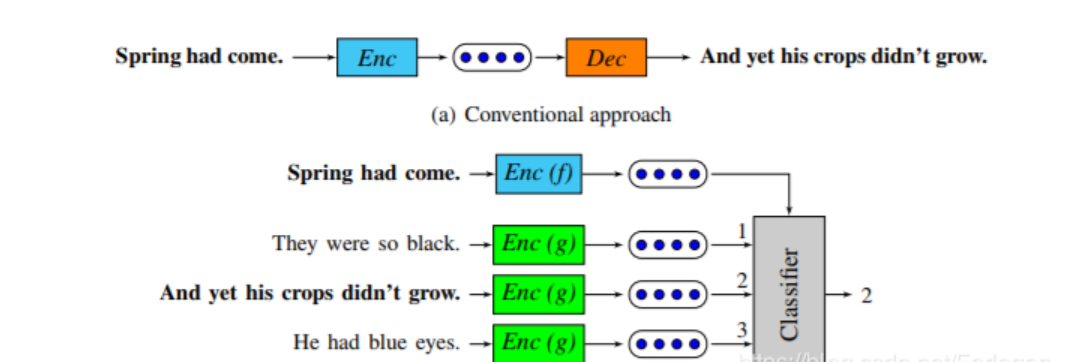
模型中的classifier吃当前句子(Spring had come.)的向量表示,还吃下一句(And yet his crops didn’t grow.)和其它几个随机生成的句子的向量表示,这个classifier可以输出正确的下一句。
classifier和encoder是一起训练的。
实作上classifier做的事情很简单,就是直接拿当前句子的向量表示和所有句子的向量表示做内积,看谁的内积最大,谁就是下一个句子。这里为了防止机器作弊,直接把输入作为下一句(这样内积最大),还要附加条件:使得当前句的向量表示和随机句子的向量表示越不像越好。
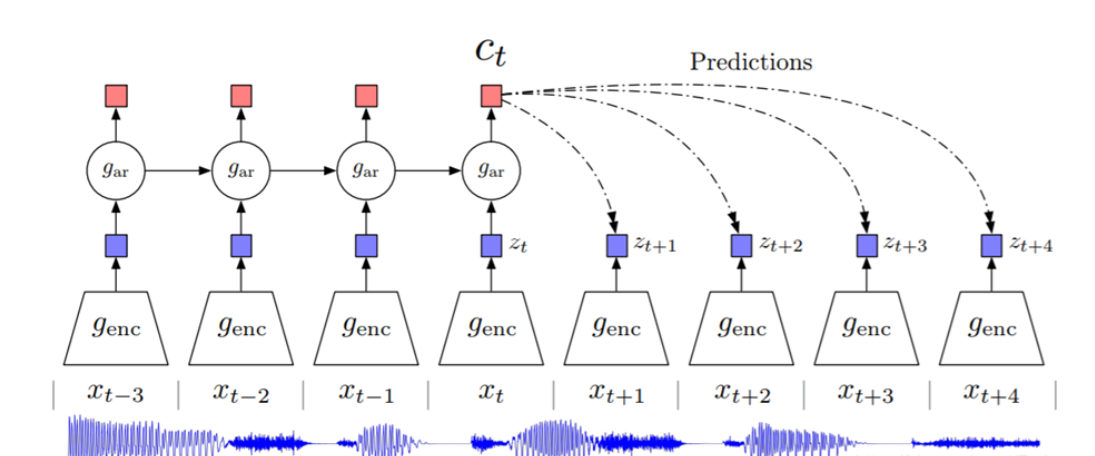
3.Contrastive Predictive Coding(CPC)
这个模型和Quick thought的思想是一样的,不过是用在声音信号上的。它称为Contrastive Predictive Coding (CPC)的技术,它同样接收一段序列数据,然后给出它的接下来数据的预测结果。模型结构如下所示,具体内容可见原论文。