torch.utils.data.DataLoader()的使用
- 作者: 我读书少你别忽悠我呀
- 来源: 51数据库
- 2021-11-22
数据加载器,结合了数据集和取样器,并且可以提供多个线程处理数据集。在训练模型时使用到此函数,用来把训练数据分成多个小组,此函数每次抛出一组数据。直至把所有的数据都抛出。就是做一个数据的初始化。
官网上对于torch.utils.data.DataLoader的讲解:
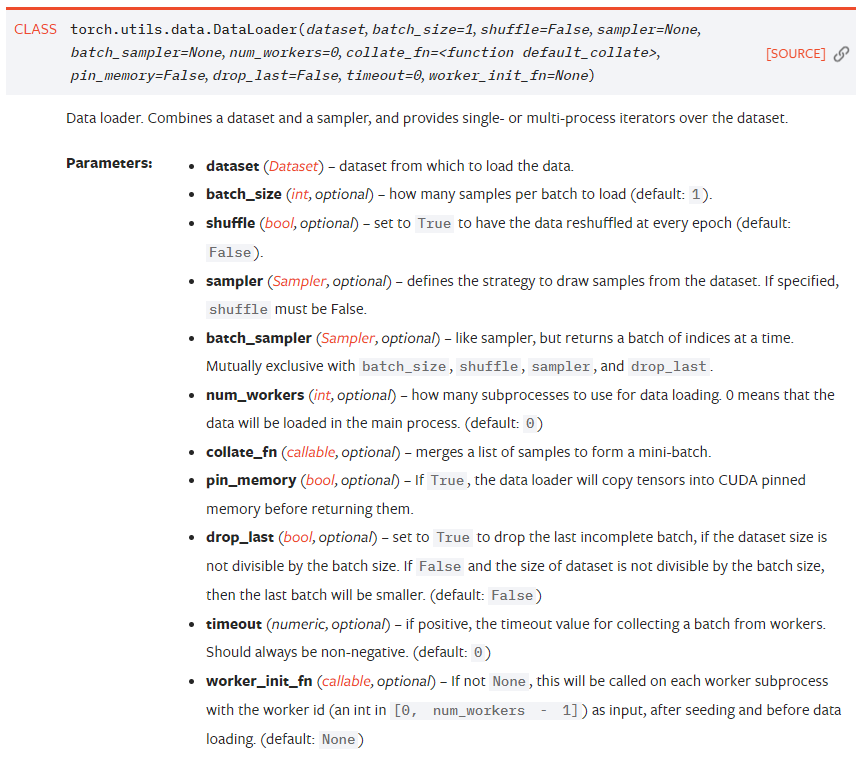
class DataLoader(object):
r"""
Data loader. Combines a dataset and a sampler, and provides
single- or multi-process iterators over the dataset.
Arguments:
dataset (Dataset): dataset from which to load the data.
batch_size (int, optional): how many samples per batch to load
(default: ``1``).
shuffle (bool, optional): set to ``True`` to have the data reshuffled
at every epoch (default: ``False``). 每个 epoch 重新随机数据
sampler (Sampler, optional): defines the strategy to draw samples from
the dataset. If specified, ``shuffle`` must be False. 定义抽样方法
batch_sampler (Sampler, optional): like sampler, but returns a batch of
indices at a time. Mutually exclusive with :attr:`batch_size`,
:attr:`shuffle`, :attr:`sampler`, and :attr:`drop_last`.
num_workers (int, optional): how many subprocesses to use for data
loading. 0 means that the data will be loaded in the main process.
(default: ``0``) 多少个线程 用于 加载数据
collate_fn (callable, optional): merges a list of samples to form a mini-batch. 把 list sample 合并成 mini-batch
pin_memory (bool, optional): If ``True``, the data loader will copy tensors
into CUDA pinned memory before returning them. If your data elements
are a custom type, or your ``collate_fn`` returns a batch that is a custom type
see the example below.
drop_last (bool, optional): set to ``True`` to drop the last incomplete batch,
if the dataset size is not divisible by the batch size. If ``False`` and
the size of dataset is not divisible by the batch size, then the last batch
will be smaller. (default: ``False``) 当 batch 很大是,最后一轮可能样本数量偏少,影响模型训练
timeout (numeric, optional): if positive, the timeout value for collecting a batch
from workers. Should always be non-negative. (default: ``0``)
worker_init_fn (callable, optional): If not ``None``, this will be called on each
worker subprocess with the worker id (an int in ``[0, num_workers - 1]``) as
input, after seeding and before data loading. (default: ``None``)
"""
下面看一个简单的使用实例:
"""
批训练,把数据变成一小批一小批数据进行训练。
DataLoader就是用来包装所使用的数据,每次抛出一批数据
"""
import torch
import torch.utils.data as Data
BATCH_SIZE = 5
x = torch.linspace(1, 10, 10) # linspace: 返回一个1维张量,包含在区间start和end上均匀间隔的step个点
y = torch.linspace(10, 1, 10)
# 把数据放在数据集中
torch_dataset = Data.TensorDataset(x, y)
loader = Data.DataLoader(
# 从数据集中每次抽出batch size个样本
dataset=torch_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=2,
)
def show_batch():
for epoch in range(3): # epoch: 迭代次数
print('Epoch:', epoch)
for batch_id, (batch_x, batch_y) in enumerate(loader):
print(" batch_id:{}, batch_x:{}, batch_y:{}".format(batch_id, batch_x, batch_y))
# print(f' batch_id:{batch_id}, batch_x:{batch_x}, batch_y:{batch_y}')
if __name__ == '__main__':
show_batch()
输出结果:
Epoch: 0
batch_id:0, batch_x:tensor([ 7., 4., 3., 9., 10.]), batch_y:tensor([4., 7., 8., 2., 1.])
batch_id:1, batch_x:tensor([6., 2., 1., 5., 8.]), batch_y:tensor([ 5., 9., 10., 6., 3.])
Epoch: 1
batch_id:0, batch_x:tensor([ 2., 7., 10., 8., 3.]), batch_y:tensor([9., 4., 1., 3., 8.])
batch_id:1, batch_x:tensor([6., 9., 1., 4., 5.]), batch_y:tensor([ 5., 2., 10., 7., 6.])
Epoch: 2
batch_id:0, batch_x:tensor([10., 3., 9., 6., 8.]), batch_y:tensor([1., 8., 2., 5., 3.])
batch_id:1, batch_x:tensor([1., 4., 2., 7., 5.]), batch_y:tensor([10., 7., 9., 4., 6.])
推荐阅读