荐 Python+Mysql爬虫之爬取Json格式数据
- 作者: 较劲_麻黄素
- 来源: 51数据库
- 2021-10-06
项目开始
1、准备事项
需要用到的包:requests、json、time、pymysql
请求路径:https://XXXX.com/js/anls-api/data/k360/numTrend/10080.do?_t=%s
这里附加说明一下,路径中10080为最长获取记录,也就是一个星期的出奖记录,获取1条记录把10080改成1即可,后面_t为服务器当前系统时间,单位为秒。
2、Json数据提取
根据url,我们用XX浏览器访问,查看数据格式,分析和查找规律后,再提取数据至mysql中存储。
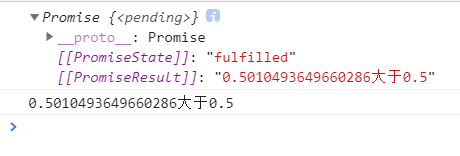
我们先利用交互式ipython获取一下当前的系统时间,如下截图:

把小数点前面的数字获取下来即可拼接到url中https://XXXX.com/js/anls-api/data/k360/numTrend/10080.do?_t=1595810996 ,访问结果如下图所示:

我们可以使用JSONView插件,把数据格式化成好看的数据,也就是Json格式数据,和python中的字典类似了。这里需要去XX商店去下载:
利用XX访问助手插件实现访问:
下载链接:安装教程请百度
链接:https://pan.baidu.com/s/17WYnX3gJ2EgVSVeeVuTWKg
提取码:lvbt
安装好插件后,我们再刷新下,看一下数据格式,找规律方便提取数据。


由上图可以看出,我们所要的数据在bodyList列表中,每一个字典下键名为openNum下的值,为一个列表,而列表中的值就是我们要提取的数据,我们通过先提取大列表,然后通过循环,把一个个数据提出来即可,然后可以保存到文件也可以,数据库也可以,在下认为保存在数据库中方便日后增删改查方便,我这里使用mysql数据库保存。程序思路了,废话不多说,那么上代码。
3、代码及展示数据
import requests
import time
import json
import pymysql
class Spider_756:
def __init__(self):
self._t = time.time()
# self.local_time = time.localtime(time.time())
self.url = 'https://75676a.com/js/anls-api/data/k360/numTrend/10080.do?_t=%s' % (self._t)
self.url_1 = 'https://75676a.com/js/anls-api/data/k360/numTrend/1.do?_t=%s' % (self._t) # 爬取一条记录
self.headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1',
'cookie': 'JSESSIONID=378756B066D3F86D6321782C06FF5954',
'Referer': 'https://75676a.com/wap/index.html',
}
self.proxy = '116.196.85.150:3128'
self.proxies = {
"http": "http://%(proxy)s/" % {'proxy': self.proxy},
"https": "http://%(proxy)s/" % {'proxy': self.proxy}
}
def get_data(self, delayed):
res = requests.get(url=self.url if delayed else self.url_1, headers=self.headers, proxies=self.proxies).text
return json.loads(res)['bodyList']
def save_all_data(self, delay):
body_list = self.get_data(delay) # 获取数据
# 创建连接对象
db_conn = pymysql.connect(host='localhost', port=3306, user='root', password='123456', database='spider756',
charset='utf8')
# 获得Cursor对象
cursor = db_conn.cursor()
# 插入原生SQL语句
insert_data = '''INSERT INTO dice(dice1,dice2,dice3,result,size,odd_even) VALUES(%s,%s,%s,%s,%s,%s);'''
for result in body_list:
temp = result['openNum']
dice1 = temp[0]
dice2 = temp[1]
dice3 = temp[2]
if (dice1 + dice2 + dice3) % 2 == 0:
temp.append(dice1 + dice2 + dice3)
temp.append('大') if (dice1 + dice2 + dice3) > 10 else temp.append('小')
temp.append('双')
try:
# 执行SQL语句
cursor.execute(insert_data, temp)
db_conn.commit()
except:
db_conn.rollback()
print("插入数据失败")
else:
temp.append(dice1 + dice2 + dice3)
temp.append('大') if (dice1 + dice2 + dice3) > 10 else temp.append('小')
temp.append('单')
try:
cursor.execute(insert_data, temp)
db_conn.commit()
except:
db_conn.rollback()
print("插入数据失败")
db_conn.close()
print(f'插入数据到数据库完成')
def run(self):
delay = True
self.save_all_data(delay)
if __name__ == '__main__':
running = Spider_756()
running.run()
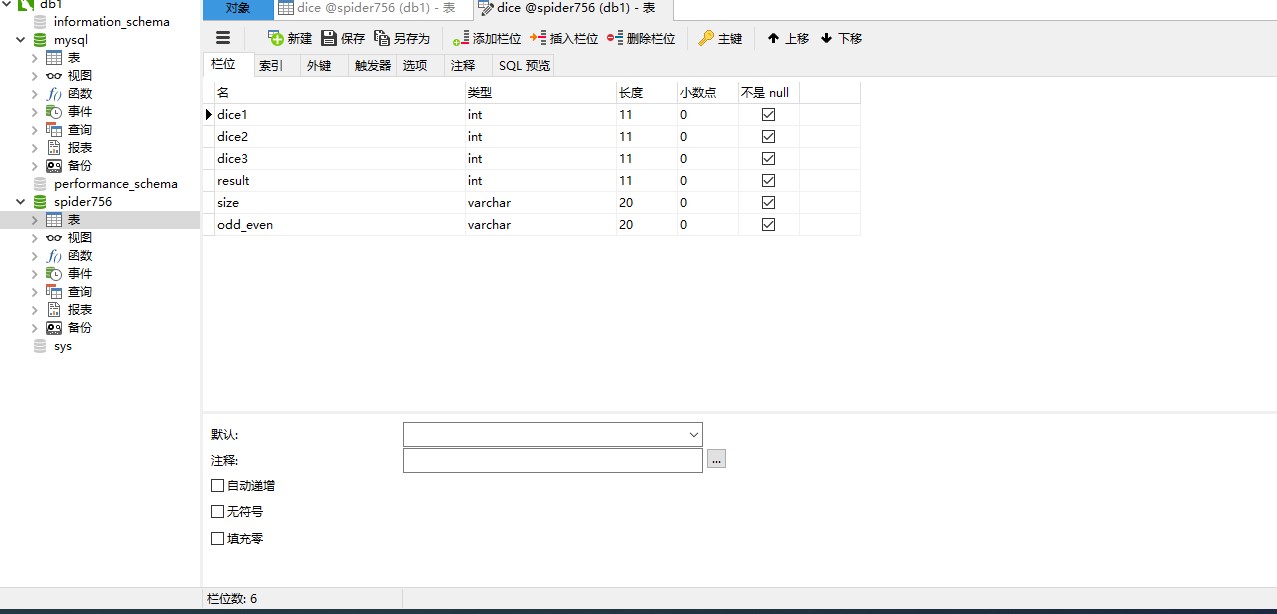
数据库需要自己先建库建表,然后在运行我的代码,这里库名和表名都在程序中体现出来,如不清楚看下面截图:
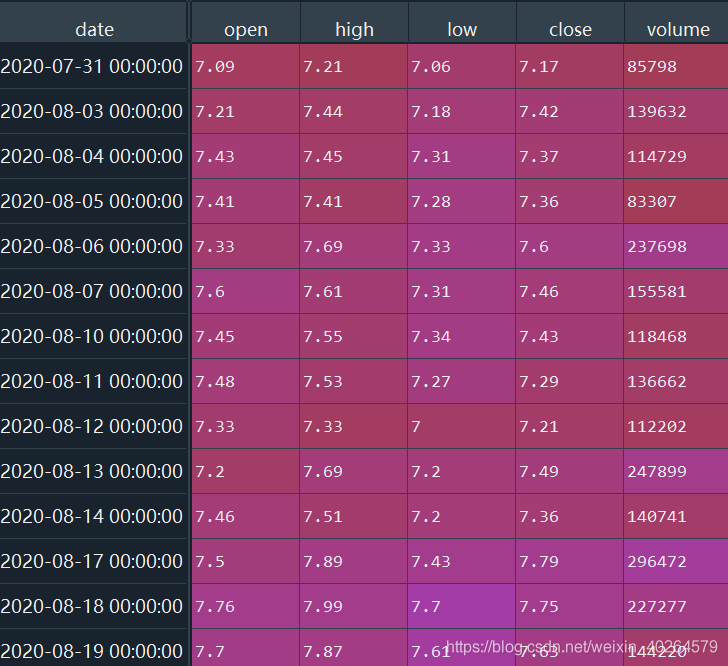
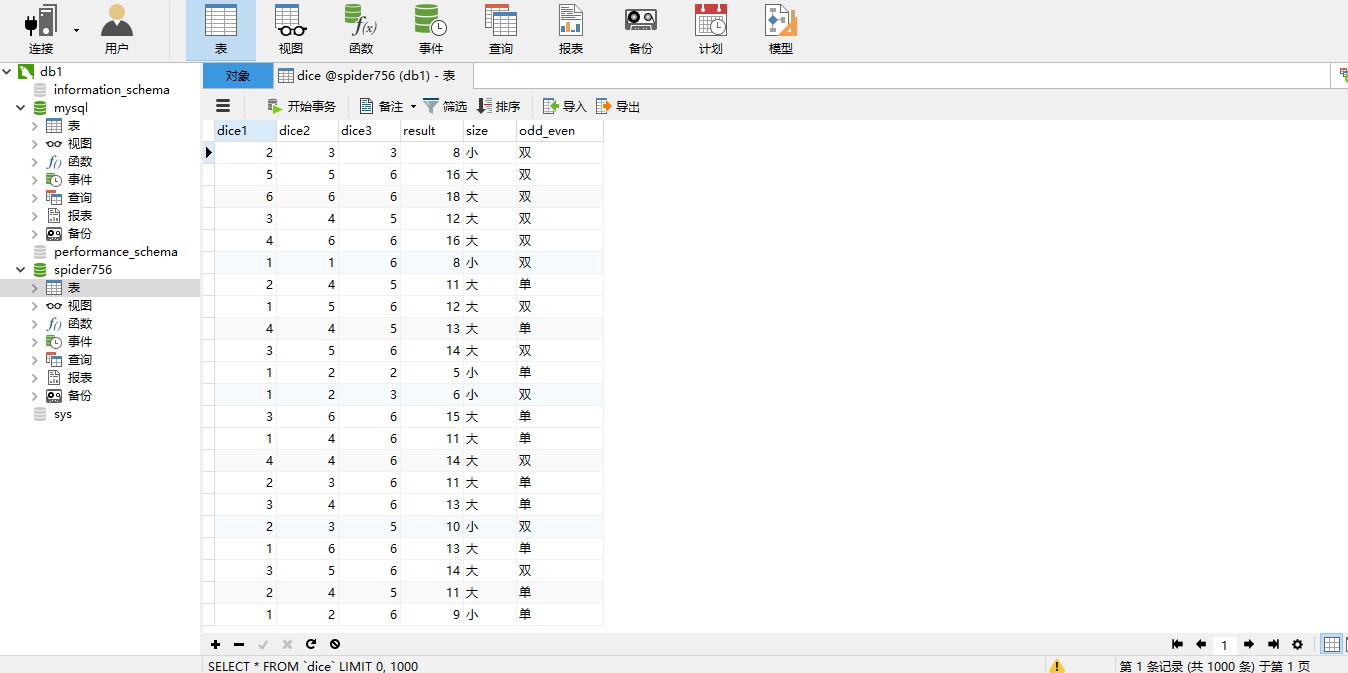
数据保存纪录如下图:
推荐阅读