Scala中正则表达式以及与模式匹配结合(多种方式)
- 作者: 用户116329088
- 来源: 51数据库
- 2021-08-15
正则表达式
//"""原生表达 val regex="""([0-9]+)([a-z]+)""".r val numpattern="[0-9]+".r val numberpattern="""\s+[0-9]+\s+""".r
说明:.r()方法简介:scala中将字符串转换为正则表达式
/** you can follow a string with `.r`, turning it into a `regex`. e.g. * * `"""a\w*""".r` is the regular expression for identifiers starting with `a`. */ def r: regex = r()
模式匹配一
//findallin()方法返回遍历所有匹配项的迭代器
for(matchstring <- numpattern.findallin("99345 scala,22298 spark"))
println(matchstring)
说明:findallin(…)函数简介
/** return all non-overlapping matches of this `regex` in the given character
* sequence as a [[scala.util.matching.regex.matchiterator]],
* which is a special [[scala.collection.iterator]] that returns the
* matched strings but can also be queried for more data about the last match,
* such as capturing groups and start position.
*
* a `matchiterator` can also be converted into an iterator
* that returns objects of type [[scala.util.matching.regex.match]],
* such as is normally returned by `findallmatchin`.
*
* where potential matches overlap, the first possible match is returned,
* followed by the next match that follows the input consumed by the
* first match:
*
* {{{
* val hat = "hat[^a]+".r
* val hathaway = "hathatthattthatttt"
* val hats = (hat findallin hathaway).tolist // list(hath, hattth)
* val pos = (hat findallmatchin hathaway map (_.start)).tolist // list(0, 7)
* }}}
*
* to return overlapping matches, it is possible to formulate a regular expression
* with lookahead (`?=`) that does not consume the overlapping region.
*
* {{{
* val madhatter = "(h)(?=(at[^a]+))".r
* val madhats = (madhatter findallmatchin hathaway map {
* case madhatter(x,y) => s"$x$y"
* }).tolist // list(hath, hatth, hattth, hatttt)
* }}}
*
* attempting to retrieve match information before performing the first match
* or after exhausting the iterator results in [[java.lang.illegalstateexception]].
* see [[scala.util.matching.regex.matchiterator]] for details.
*
* @param source the text to match against.
* @return a [[scala.util.matching.regex.matchiterator]] of matched substrings.
* @example {{{for (words <- """\w+""".r findallin "a simple example.") yield words}}}
*/
def findallin(source: charsequence) = new regex.matchiterator(source, this, groupnames)

模式匹配二
//找到首个匹配项
println(numberpattern.findfirstin("99ss java, 222 spark,333 hadoop"))

模式匹配三
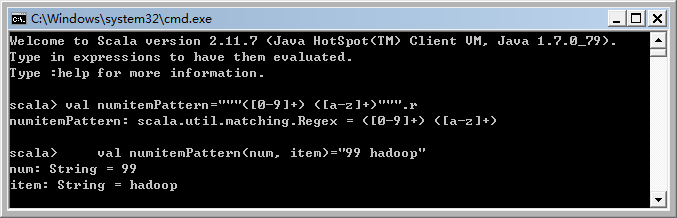
//数字和字母的组合正则表达式 val numitempattern="""([0-9]+) ([a-z]+)""".r val numitempattern(num, item)="99 hadoop"
模式匹配四
//数字和字母的组合正则表达式
val numitempattern="""([0-9]+) ([a-z]+)""".r
val line="93459 spark"
line match{
case numitempattern(num,blog)=> println(num+"\t"+blog)
case _=>println("hahaha...")
}

val line="93459h spark"
line match{
case numitempattern(num,blog)=> println(num+"\t"+blog)
case _=>println("hahaha...")
}

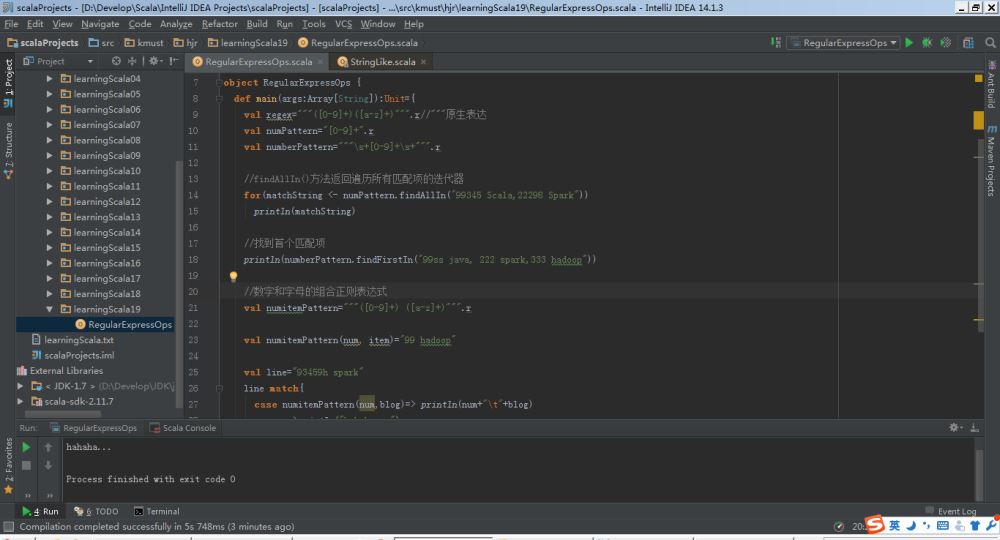
本节所有程序源码
package kmust.hjr.learningscala19
/**
* created by administrator on 2015/10/17.
*/
object regularexpressops {
def main(args:array[string]):unit={
val regex="""([0-9]+)([a-z]+)""".r//"""原生表达
val numpattern="[0-9]+".r
val numberpattern="""\s+[0-9]+\s+""".r
//findallin()方法返回遍历所有匹配项的迭代器
for(matchstring <- numpattern.findallin("99345 scala,22298 spark"))
println(matchstring)
//找到首个匹配项
println(numberpattern.findfirstin("99ss java, 222 spark,333 hadoop"))
//数字和字母的组合正则表达式
val numitempattern="""([0-9]+) ([a-z]+)""".r
val numitempattern(num, item)="99 hadoop"
val line="93459h spark"
line match{
case numitempattern(num,blog)=> println(num+"\t"+blog)
case _=>println("hahaha...")
}
}
}
总结
以上所述是小编给大家介绍的scala中正则表达式以及与模式匹配结合(多种方式),希望对大家有所帮助
推荐阅读

