Hash存储模型、B-Tree存储模型、LSM存储模型介绍
- 作者: 温颠唉
- 来源: 51数据库
- 2020-08-06
每一种数据存储系统,对应有一种存储模型,或者叫存储引擎。我们今天要介绍的是三种比较流行的存储模型,分别是:
- Hash存储模型
- B-Tree存储模型
- LSM存储模型
不同存储模型的应用情况
1、Hash存储模型
- redis
- memcache
2、B-Tree存储模型
- MySQL(以及大多数的关系型数据库)
- MongoDB
3、LSM树存储模型
- HBase
- RocksDB
不同存储模型介绍
1、Hash存储模型
Hash存储模型其实就是HashMap(哈希表)的持久化实现。这种模型的特点是与HashMap有密切关系的。我们知道HashMap可以支持:put(key)增加/修改、delete(key)删除、get(key)随机获取操作,但是HashMap不支持get(1)这样的操作。因为HashMap是无序的,不支持顺序扫描。针对put、get操作,它的时间复杂度是O(1),也就是说读写速度都很快,所以针对单个Key的操作是非常快速的。如果我们在应用中无需遍历数据,Hash引擎是非常合适的。

首先,通过key,找到对应的文件编号。这个检索的过程,是通过HashMap来实现的。
其次,通过文件编号找到存储中的文件
再者,通过value长度和位置找到对应的行数据
最后,读取出value内容
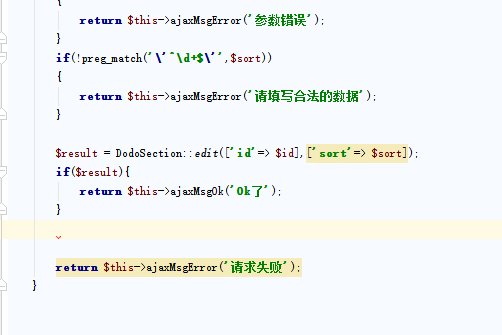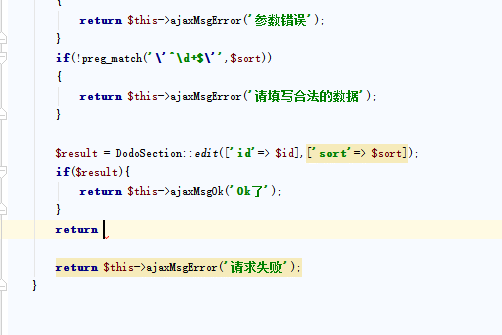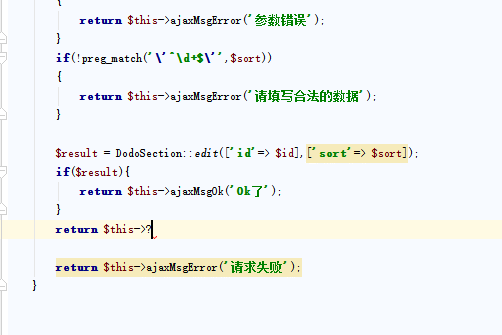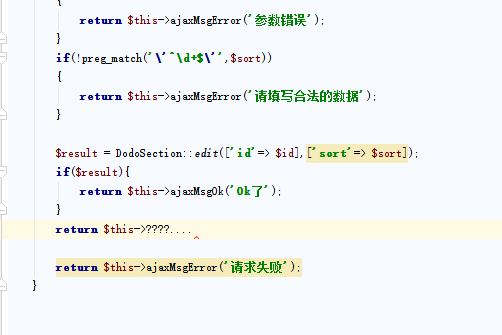
2、B-Tree存储模型
B-Tree存储模型由于是树状结构存储,所以,它是不支持随机读写的。就像我们学习二叉树时,查找数据得通过遍历树的方式来查找数据。

上图是一种典型的B-Tree存储索引。叶子节点保存了每行的完整数据,非叶子节点保存了索引信息。数据在每个节点都是有序存储的,但查询数据的时候,需要从根节点遍历,然后根据二分查找直到找到叶子节点。如果数据不再内存中,需要从磁盘中读取,并加载到缓存。B+树的根节点是常驻内存的,最多需要h-1次磁盘IO,复杂度为O(h) = O(logdN)。修改操作首先要记录提交日志,然后在修改内存中的B+树。
3、LSM树存储引擎
LSM树的思想很容易理解,就是将数据的新增、修改增量数据先保存在内存中,到达指定的大小限制后将修改操作批量写入到磁盘。读取时,需要合并磁盘中的历史数据和内存中最近的修改操作。LSM的优势在于有效地随机写入问题,但读取可能需要访问较多的磁盘文件。

- Level 0 :日志/内存
- 先写入预写日志,再写内存
- 写入日志是为了保障可用性
- Level 1:日志/内存,当Level 0写入达到阈值,通过异步方式将部分数据刷写到硬盘上
- Level 2:合并,由于不断刷写会产生大量小文件,这样不利于管理和查询。需要在合适的时机启动一个异步线程进行合并操作生成一个大文件
原文链接:http://www.cnblogs.com/ilovezihan/p/12260893.html