mapreduce 体系结构
- 作者: 撩起裙摆
- 来源: 51数据库
- 2020-09-29
主要分为以下几个部分:
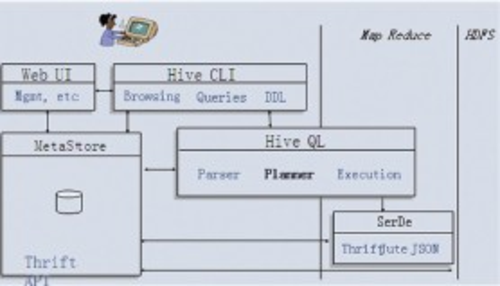
用户接口
用户接口主要有三个:CLI,Client 和 WUI。其中最常用的是 CLI,Cli 启动的时候,会同时启动一个 Hive 副本。Client 是 Hive 的客户端,用户连接至 Hive Server。在启动 Client 模式的时候,需要指出 Hive Server 所在节点,并且在该节点启动 Hive Server。 WUI 是通过浏览器访问 Hive。
元数据存储
Hive 将元数据存储在数据库中,如 mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
解释器、编译器、优化器、执行器
解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后由 MapReduce 调用执行。
Hadoop
Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(包含 * 的查询,比如 select * from tbl 不会生成 MapReduce 任务)。
应该是hadoop在hbase和hive中的作用吧。 hbase与hive都是架构在hadoop之上的。都是用hadoop作为底层存储。而hbase是作为分布式数据库,而hive是作为分布式数据仓库。当然hive还是借用hadoop的mapreduce来完成一些hive中的命令的执行。而hbase与hive都是单独安装的。你需要哪个安装哪个,所以不存在重复信息。
用户接口
用户接口主要有三个:CLI,Client 和 WUI。其中最常用的是 CLI,Cli 启动的时候,会同时启动一个 Hive 副本。Client 是 Hive 的客户端,用户连接至 Hive Server。在启动 Client 模式的时候,需要指出 Hive Server 所在节点,并且在该节点启动 Hive Server。 WUI 是通过浏览器访问 Hive。
元数据存储
Hive 将元数据存储在数据库中,如 mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
解释器、编译器、优化器、执行器
解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后由 MapReduce 调用执行。
Hadoop
Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(包含 * 的查询,比如 select * from tbl 不会生成 MapReduce 任务)。
应该是hadoop在hbase和hive中的作用吧。 hbase与hive都是架构在hadoop之上的。都是用hadoop作为底层存储。而hbase是作为分布式数据库,而hive是作为分布式数据仓库。当然hive还是借用hadoop的mapreduce来完成一些hive中的命令的执行。而hbase与hive都是单独安装的。你需要哪个安装哪个,所以不存在重复信息。
推荐阅读

