Golang中time.After的使用理解与释放问题
- 作者: 迷茫居士71979789
- 来源: 51数据库
- 2021-10-12
golang中的time.after的使用理解
关于在goroutine中使用time.after的理解, 新手在学习过程中的“此时此刻”的理解,错误还请指正。
先线上代码:
package main
import (
"fmt"
"time"
)
func main() {
//closechannel()
c := make(chan int)
timeout := time.after(time.second * 2) //
t1 := time.newtimer(time.second * 3) // 效果相同 只执行一次
var i int
go func() {
for {
select {
case <-c:
fmt.println("channel sign")
return
case <-t1.c: // 代码段2
fmt.println("3s定时任务")
case <-timeout: // 代码段1
i++
fmt.println(i, "2s定时输出")
case <-time.after(time.second * 4): // 代码段3
fmt.println("4s timeout。。。。")
default: // 代码段4
fmt.println("default")
time.sleep(time.second * 1)
}
}
}()
time.sleep(time.second * 6)
close(c)
time.sleep(time.second * 2)
fmt.println("main退出")
}
主要有以上4点是我们平时遇到的。
首先遇到的问题是:
如上的代码情况下, 代码段3处的case 永远不执行, 无论main进程执行多久。这是为什么呢?
首先我们分析为啥不执行代码段3, 而是程序一直执行的是default. 由此我们判断:
case <- time.after(time.second) :
是本次监听动作的超时时间, 意思就说,只有在本次select 操作中会有效, 再次select 又会重新开始计时(从当前时间+4秒后), 但是有default ,那case 超时操作,肯定执行不到了。
那么问题就简单了我们预先定义了计时操作:
case <- timeout:
在goroutine开始前, 我们记录了时间,在此时间3s之后进行操作。相当于定时任务, 并且只执行一次。 代码段1和代码段2 实现的结果都相同
针对以上问题解决后,我写了一个小案例:
package main
import (
"fmt"
"time"
)
//发送者
func sender(c chan int) {
for i := 0; i < 100; i++ {
c <- i
if i >= 5 {
time.sleep(time.second * 7)
} else {
time.sleep(time.second)
}
}
}
func main() {
c := make(chan int)
go sender(c)
timeout := time.after(time.second * 3)
for {
select {
case d := <-c:
fmt.println(d)
case <-timeout:
fmt.println("这是定时操作任务 >>>>>")
case dd := <-time.after(time.second * 3):
fmt.println(dd, "这是超时*****")
}
fmt.println("for end")
}
}
执行结果:
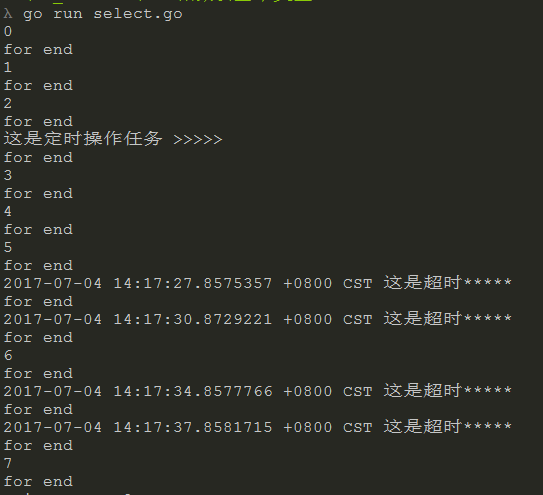
要注意的是,虽然执行到i == 6时, 堵塞了,并且执行了超时操作, 但是下次select 依旧去除的是6
因为通道中已经发送了6,如果未取出,程序堵塞。
golang中time.after释放的问题
在谢大群里看到有同学在讨论time.after泄漏的问题,就算时间到了也不会释放,瞬间就惊呆了,忍不住做了试验,结果发现应该没有这么的恐怖的,是有泄漏的风险不过不算是泄漏,先看api的说明:
// after waits for the duration to elapse and then sends the current time
// on the returned channel.
// it is equivalent to newtimer(d).c.
// the underlying timer is not recovered by the garbage collector
// until the timer fires. if efficiency is a concern, use newtimer
// instead and call timer.stop if the timer is no longer needed.
func after(d duration) <-chan time {
return newtimer(d).c
}
提到了一句the underlying timer is not recovered by the garbage collector,这句挺吓人不会被gc回收,不过后面还有条件until the timer fires,说明fire后是会被回收的,所谓fire就是到时间了,写个例子证明下压压惊:
package main
import "time"
func main() {
for {
<- time.after(10 * time.nanosecond)
}
}
显示内存稳定在5.3mb,cpu为161%,肯定被gc回收了的。当然如果放在goroutine也是没有问题的,一样会回收:
package main
import "time"
func main() {
for i := 0; i < 100; i++ {
go func(){
for {
<- time.after(10 * time.nanosecond)
}
}()
}
time.sleep(1 * time.hour)
}
只是资源消耗会多一点,cpu为422%,内存占用6.4mb。因此:
remark: time.after(d)在d时间之后就会fire,然后被gc回收,不会造成资源泄漏的。
那么api所说的if efficieny is a concern, user newtimer instead and call timer.stop是什么意思呢?这是因为一般time.after会在select中使用,如果另外的分支跑得更快,那么timer是不会立马释放的(到期后才会释放),比如这种:
select {
case time.after(3*time.second):
return errtimeout
case packet := packetchannel:
// process packet.
}
如果packet非常多,那么总是会走到下面的分支,上面的timer不会立刻释放而是在3秒后才能释放,和下面代码一样:
package main
import "time"
func main() {
for {
select {
case <-time.after(3 * time.second):
default:
}
}
}
这个时候,就相当于会堆积了3秒的timer没有释放而已,会不断的新建和释放timer,内存会稳定在2.8gb,这个当然就不是最好的了,可以主动释放:
package main
import "time"
func main() {
for {
t := time.newtimer(3*time.second)
select {
case <- t.c:
default:
t.stop()
}
}
}
这样就不会占用2.8gb内存了,只有5mb左右。因此,总结下这个after的说明:
- gc肯定会回收time.after的,就在d之后就回收。一般情况下让系统自己回收就好了。
- 如果有效率问题,应该使用timer在不需要时主动stop。大部分时候都不用考虑这个问题的。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对的支持。

