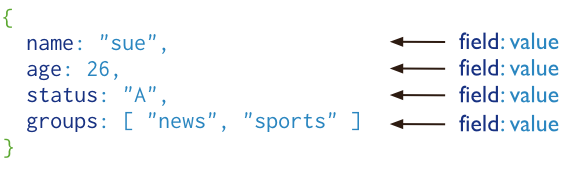MongoDB指南/引言
- 作者: 90后农民工工头
- 来源: 51数据库
- 2020-08-08
引言MongoDB是一种开源文档型数据库,它具有高性能,高可用性,自动扩展性 1. 文档数据库MongoDB用一个文档来表示一条记录,文档的数据结构由键值对组成。MongoDB文档类似于JSON对象,字段值可能是文档,数组,或文档数组。
使用文档的优点:
2. 主要特性高性能 MongoDB支持高性能数据存储。特别地:
丰富的查询语言 MongoDB提供了丰富的查询语言以支持读写操作和聚集操作、文本检索、地理信息查询 高可用性 MongoDB的复制能力被称作复制集( replica set ),它提供了自动的故障迁移和数据冗余。一个复制集是一组包含了相同数据的多台 MongoDB服务器,它提供了冗余性和加强了数据的可用性。 横向扩展 MongoDB的横向扩展能力是其核心功能的一部分:
支持多存储引擎 包括: WiredTiger Storage Engine , MMAPv1 Storage Engine 。此外, MongoDB 提供 可插拔存储引擎 API , 允许第三方开发者为 MongoDB开发存储引擎。 3. 数据库和集合MongoDB 存储BSON文档,例如数据记录在集 合 中,集 合 在数据库中。
3.1 数据库 在 MongoDB 中数据库持有集 合 。 在 Mongo shell中,选 中 一个数据库使用如下命令: use <db> ,例如: use myDB 创建数据库 如果待操作的数据库不存在,那么在第一次 向 MongoDB 存储数据 时, MongoDB会创建这个数据库。例如,使用如下命令操作一个不存在的数据库。 use myNewDB db.myNewCollection1.insert( { x: 1 } ) insert() 操作创建了 数据库 myNewDB,若 集合 myNewCollection1也不存在,同样地 集合 myNewCollection1也被创建。 3.2 集 合 MongoDB 在集 合 中存储文档,集 合 类似于关系数据库中的表。 创建一个集 合 如果一个集 合 不存在,使用下面命令时 集合 会被创建: db.myNewCollection2.insert( { x: 1 } ) db.myNewCollection3.createIndex( { y: 1 } ) insert() 和 createIndex() 在集 合 不存在的情况下会创建集 合 。 显式创建集合 MongoDB 提供了 db.createCollection() 方法来显示地创建一个集 合 。可以为创建的集合指定参数,例如设置集合的大小或者文档的验证规则,如果不需要指定这些参数,那么没必要显示地创建一个集 合 。 文档验证 ( 3.2版新特性) 默认情况下,一个集 合 中的文档不必具有相同的结构 , 一个集中的文档不需要具有 一系列 相同的字段,并且不同文档中字段的数据类型可以不同。 修改文档结构 可以更改集 合 中的文档结构,如添加新字段,删除现有字段,或将字段值更改为一种新的类型,更新文档结构 3.3 固定集 合3.3.1 概述 固定集 合 ,即具有固定大小的集 合 ,它支持基于插入顺序的插入和查询这两种高通量操作。固定大小的集 合 的工作方式类似于循环缓存:一旦一个集 合 被填满,待插入的文档会覆盖掉最先插入的文档。 3.3.2 行为 插入顺序 固定集 合 保证了插入顺序,因此对于查询操作而言,不需要索引的支持就可以返回多个按顺序排列的文档。没有索引的开销,固定集 合 支持更高的插入吞吐量。 自动删除最先插入的文档 为了给新文档让出存储空间,固定集 合 自动删除最先插入的文档而不需要显示的删除操作。 例如,集合 oplog.rs 中存储了 副本集 操作日志,这里 副本集 使用了固定集 合 。考虑下面对固定集 合 可能的操作:
_id 字段索引 固定集 合 含有 _id字段,此字段索引是默认的。 3.3.3 限制和建议 更新 如果你要更新固定集合中的文档,创建索引以防止全表扫描。 文档大小 ( 3.2版本变更) 如果更新或替换操作改变了文档大小,则操作失败 。 删除文档 不能删除固定集合中的文档,可使用 drop() 命令删除整个固定集 合 并新建之。 分片 固定集合不允许分片 。 查询效率 使用自然排序可高效地检索最新插入的元素。这是(有点)像 追踪一个 日志文件。 聚集操作符 $out 不能使用聚集管道操作符 $out 将结果写入固定集合 3.3.4 过程 创建固定集合 在 mongoshel 中, 使用 db.createCollection() 方法创建固定集 合 ,创建固定集 合 的时候要指定集 合 的字节大小, MongoDB将会提前为所创建的固定集合分配存储空间。固定集合的字节大小包含了内部使用的空间大小。 db.createCollection( "log", { capped: true, size: 100000 } ) 如果字段的字节大小小于等于 4096 字节 ,那么固定集 合 的 字节 大小为 4096 字节 。否则 MongoDB 会将给定值提升为 256 字节的整数倍。 另外,你可以使用 max 字段设置集合中文档的最大数量: db.createCollection("log", { capped : true, size : 5242880, max : 5000 } ) 注意:对 size 的设置是必须的。在集合中的文档数量还未达到最大值而集合的字节大小已经达到最大时, MongoDB 同样会移除最先插入的文档。 查询固定集合 如果使用 find() 方法查询固定集合而没有指定排序规则,查询返回结果的排序和文档插入时的排序是一样的。 为了使查询结果的排序与插入时相反,可以使用 sort() 方法并将 $natural 参数设置为 -1: db.cappedCollection.find().sort( { $natural: -1 } ) 检查集合是否为固定集合 使用 isCapped() 方法检查集合是否为固定集合: db.collection.isCapped() 将集合转换为固定集合 使用 convertToCapped 命令将一个非固定集合转换为固定集合: db.runCommand({"convertToCapped": "mycoll", size: 100000}); size 参数设定了固定集合的字节大小 。 警告:这个命令将会获得全局写入锁,它会阻塞其他操作直到此操作完成为止。 在指定的一段时间后自动移除数据 对于数据过期的情形,为支持额外的灵活性,可使用 MongoDB 的 TTL 索引。这些索引允许你利用一种特殊的类型使数据过期并从普通集合中移除,这种特殊的类型是基于时间字段值和 TTL值的。 TTL集合与固定集合不兼容。 Tailable 游标 对于固定集合,可以使用 Tailable 游标。 Tailable游标类似于Unix 的 tail -f 命令, Tailable 游标 追 踪固定集合的末端。新文档插入固定集合的同时,可以使用 Tailable游标检索文档。 4. 文档MongoDB将数据存储为BSON 文档, BSON是一个JSON文档的二进制表示形式,但它所包含的数据类型比JSON多。
4.1 文档结构 MongoDB文档是由键值对构成的,形式如下: { field1: value1, field2: value2, field3: value3, ... fieldN: valueN } 字段值的类型可以是任何 BSON类型,包括:文档,数组,文档数组,例如: var mydoc = { _id: ObjectId("5099803df3f4948bd2f98391"), name: { first: "Alan", last: "Turing" }, birth: new Date('Jun 23, 1912'), death: new Date('Jun 07, 1954'), contribs: [ "Turing machine", "Turing test", "Turingery" ], views : NumberLong(1250000) } 上面的例子包括以下类型:
字段名称 字段的名称是字符串。 对于字段的命名有下面的约束:
BSON 文档允许有相同的字段名称。大多数的 MongoDB接口不支持字段名称重复。如果需要重复的字段名称,请查看 你所使用的 驱动文档。 MongoDB内部处理程序 创建的 文档可能会有 重名的字段 ,但不会向用户文档中添加 重名 字段。 字段值约束 对于已经索引的集合来说,索引字段值有最大索引键值长度限制。 4.2 圆点记法 MongoDB使用圆点符号来访问数组中的元素和嵌入式文档字段。 数组 MongoDB中数组是基于0索引的。使用圆点连接集合名称和索引位置: "<array>.<index>" 例如,给定下面的文档 { ... contribs: [ "Turing machine", "Turing test", "Turingery" ], ... } 为了访问第三个元素,可以这样: contribs.2 嵌入式文档 使用圆点连接嵌入式文档名称和文档字段名称: "<embedded document>.<field>" 例如,给定下面的文档 { ... name: { first: "Alan", last: "Turing" }, contact: { phone: { type: "cell", number: "111-222-3333" } }, ... }
4.3 文档约束 文档大小约束 BSON 文档最大为 16MB。设置单个文档大小的最大值 有助于确保单个文档不会 耗尽系统内存,或者在传输的过程中不会占用太多的带宽。为了能够存储超过最大值的文档, MongoDB提供了GridFS API 。 文档字段顺序 除以下情况外, MongoDB保持写入时的字段顺序:
从 2.6版本开始MongoDB保持写入时的字段顺序,但之前的版本并非如此。 _id字段 在 MongoDB中,文档需要_id字段作为主键,如果插入文档时没有指定_id字段,MongoDB会使用ObjectIds 作为默认的 _id的默认值。例如,向集合中插入一个不包含位于文档开始处的_id字段的文档,MongoDB会将_id添加进来并且其类型为ObjectIds 。 另外,如果 Mongod接收一个 待 插入的不包含 _id字段的文档,Mongod将会添加一个ObjectIds 类型的字段。 _id字段有下列行为和约束:
警告:为了保证复制功能,不要在 _id字段存储BSON 正则表达式类型。 下面是 关于 _id字段值 的常见选项 :
binary subtype 值取值范围为 0-7 或 128-135 字节数组的长度是: 0,1,2,3,4,5,6,7,8,10,12,14,16,20,24或32.
4.4 文档结构其他用途 除了定义数据记录, MongoDB使用文档结构贯穿始终,包括但不限于:查询过滤器,更新规范文档,索引规范文档。 查询过滤器文档 查询过滤器文档指定了检索,更新,删除文档的条件。 可以使用 <field>:<value> 表达式来指定相等条件和查询运算符表达式。 { <field1>: <value1>, <field2>: { <operator>: <value> }, ... } 更新规范文档 在 db.collection.update()方法执行期间,更新规范文档使用更新运算符指明待修改字段。 { <operator1>: { <field1>: <value1>, ... }, <operator2>: { <field2>: <value2>, ... }, ... } 索引规范文档 索引规范文档定义了要索引的字段和索引类型。 { <field1>: <type1>, <field2>: <type2>, ... } 5. BSON 类型BSON是 一种 用来存储文档和 MongoDB执行远程调用的二进制序列化格式。BSON规范位于bsonspec.org。 BSON支持以下数据类型,每种数据类型都有一个相应的数字和字符串别名,可以使用别名和$type操作符基于类型匹配模式检索文档。
5.1 比较 /排序顺序 当比较不同 BSON类型的值时,MongoDB使用下面的比较顺序,从最低到最高: 1.MinKey (内部类型) 2.Null 3.Numbers (ints, longs, doubles) 4.Symbol, String 5.Object 6.Array 7.BinData 8.ObjectId 9.Boolean 10.Date 11.Timestamp 12.Regular Expression 13.MaxKey (内部类型) 对于比较而言, MongoDB将一些类型看作是等价的。例如,数值类型在比较之前执行转换。 3.0.0版本的变化:Date 排 在 Timestamp 之前 。 之前的 版本, Date和Timestamp 排序相同 。 对于比较而言, MongoDB将不存在的字段看作空BSON 对象,例如,对{ } 和{ a: null }在排序中被看作是等价的。 对于数组而言,小于比较或者升序排序比较 的是 数组中最小的元素,大于比较或者降序排序比较 的是 数组中最大的元素。例如,比较一个只有一个元素的数组类型字段(例如 [ 1 ]) )和非数组字段(例如 2),比较的是1和2。 空数组 (例如 []) 的比较被看作是小于空 (null) 或被看作丢失的字段。 对于 BinData 类型,按下面顺序排序: 1.首先, 按数据的长度或大小排序 。 2. 然后 , 按 BSON一个字节子类型排序 。 3. 最后 , 一个字 节 一个字节地比较 。 下面的章节针对特定的 BSON类型描述了特别的注意事项: 5.2 ObjectId ObjectId占据存储空间小、唯一、可被快速生成和索引。ObjectId 类型 值为 12字节,前四个字节是一个时间戳,表示其被创建的时间:
在 MongoDB中,集合中的文档需要一个作为主键的唯一_id字段,如果没有指定_id字段,MongoDB默认将ObjectId 类型值 作为 _id字段值。 例如,待插入文档不包含顶级 _id字段,MongoDB 驱动就会添加一个 ObjectId 类型的 _id字段 。 另外,如果 mongod接收的 待插入文档不包含 _id字段,mongod 将会添加一个 ObjectId 类型 的 _id字段。 MongoDB 客户端应该添加一个值为 ObjectId的_id字段,使用值为ObjectId的_id字段有如下好处:
重要的: 在一秒之内, ObjectId值的顺序与生成时间之间的关系并不是严格的。如果单系统中,多个系统或多个进程或多个线程在一秒内产生了多个ObjectId值,这些值并不会严格地按照插入顺序展示。多客户端之间的时钟偏移也会导致不严格排序,即使这些值由客户端驱动程序生成。 5.3 String BSON 的 String类型是UTF-8编码的。一般来说,每种语言对应的驱动程序在执行序列化和 反 序列化 BSON时将语言自身的string类型转换为UTF-8编码,这使得BSON string可以接受大多数国际字符。另外,使用$regex 查询支持 UTF-8编码的正则表达式字符。 5.4 Timestamp BSON 中有一个特殊的时间戳类型 供 MongoDB内部使用,并且不能和Date 配合使用。时间戳类型是 64位的值:
在一个 mongod实例中,时间戳的值是唯一的。 在复制功能中, oplog有一个ts字段,字段值使用DSON时间戳,它反映了操作时间。 注: BSON时间戳类型 ( Timestape) 是供 MongoDB内部使用的。大多数情况下,开 发 应用程序时使用 Date类型。 如果你 所 插入文档 的 顶级字段是一个空值的时间戳类型 ( Timestape) , MongoDB 服务器将会用当前的时间戳 ( Timestape) 替换它。例如执行下面的操作: var a = new Timestamp(); db.test.insert( { ts: a } ); 然后,使用 db.test.find() 方法查询,返回结果为: { "_id" : ObjectId("542c2b97bac0595474108b48"), "ts" : Timestamp(1412180887, 1) } 如果 ts是嵌入式文档的一个字段,服务器会保持其为空值。 2.6版本中的变化:以前当插入文档时,服务器仅仅会替换头两个空值时间戳类型 ( Timestape) 字段,包括 _id字段。现在服务器会替换任何的顶级字段。 5.5 Date BSON 日期类型是 64位整型,表示从UNIX新纪元(Jan 1, 1970 )来的毫秒数。这一结果表示了可表达的约 2亿9000万年范围内的过去和未来。 官方的 BSON规范指出DSON日期类型是通用协调时间(UTC datetime )。 BSON日期类型是有符号的,负值表示1970年之前的日期。 例如: 在 mongo shell中,使用new Date() 构建日期: var mydate1 = new Date() 在 mongo shell中,使用ISODate() 构建日期: var mydate2 = ISODate() 返回时间值的字符串: mydate1.toString() 返回日期中的月份,日期是基于 0索引的,所以一月 份 就是: mydate1.getMonth() 6. MongoDB对JSON的扩展JSON所表示的类型仅是BSON数据类型的子集。为了表示类型信息,MongoDB对JSON做如下扩展:
这种 形式 被用于各种数据类型,这些类型依赖于 JSON被解析的上下文环境。 6.1 解析器和支持的格式 以 strict模式输入 以下能够解析 strict模式 形式 ,识别类型信息。
其他的 JSON解析器,包括mongoshell 和 db.eval() 能够解析键值对形式的 strict模式表示,但是不能够识别类型信息。 以 mongo Shell 模式输入 以下能够解析 mongo Shell模式表达,识别类型信息。
以 strict模式输出 mongoexport 和 REST and HTTP Interfaces 以 Strict模式输出数据。 以 mongo Shell 模式输出 bsondump 以 mongo Shell 模式输出数据。 6.2 BSON数据类型和相关的描述 下面展示了 strict模式和mongo Shell模式的一些BSON数据类型及相关描述。 Binary
Date
在 strict模式中,<date> 是 ISO-8601 数据格式的强制性时区字段,它的模板为: YYYY-MM-DDTHH:mm:ss.mmm<+/-Offset> 。 当前的 MongoDB JSON解析器不支持加载Unix 新纪元 之前的 ISO-8601 字符串日期。当格式化系统的 time_t 类型 的纪元之前和之后的 时间时, 采用 下面的格式: { "$date" : { "$numberLong" : "<dateAsMilliseconds>" } } 在 Shell 模式中, <date> 是一个 64字节有符号整数 的 JSON 形式 ,这个整数 的 表示形式 为 协调世界时间( UTC)的毫秒数。 Timestamp
Regular Expression ( 正则表达式)
OID
<id> 是 一个 24字符的十六进制字符串 。 DB Reference
Undefined Type
表示为 JavaScript/BSON 中未定义类型。 查询文档时不能使用未定义类型。将下面的文档插入 people 集合: db.people.insert( { name : "Sally", age : undefined } ) 下面的查询 会 返回一个错误: db.people.find( { age : undefined } ) db.people.find( { age : { $gte : undefined } } ) 然而,可使用 $type 查询未定义类型: db.people.find( { age : { $type : 6 } } ) 这个查询返回所有 age 字段 为未定义类型 的文档。 MinKey
Minkey BSON数据类型的 排序 低于所有其他类型。 MaxKey
MaxKey BSON 数据类型的 排序 高于所有其他类型。 NumberLong ( 2.6版本新增 )
NumberLong 是 64位有符号整数,必须使用引号否则它将会被理解为浮点型,这会导致精度丢失。 例如,插入 9223372036854775807 , 却没有将其用引号括起来: db.json.insert( { longQuoted : NumberLong("9223372036854775807") } ) db.json.insert( { longUnQuoted : NumberLong(9223372036854775807) } ) 当查询文档时, longUnquoted 的值改变了,而 longQuoted 的值没变。 执行 db.json.find() , 返回结果为: { "_id" : ObjectId("54ee1f2d33335326d70987df"), "longQuoted" : NumberLong("9223372036854775807") } { "_id" : ObjectId("54ee1f7433335326d70987e0"), "longUnquoted" : NumberLong("-9223372036854775808") } |