Django实现whoosh搜索引擎使用jieba分词
- 作者: 权鸿
- 来源: 51数据库
- 2020-08-06
本文介绍了Django实现whoosh搜索引擎使用jieba分词,分享给大家,具体如下:
Django版本:3.0.4
python包准备:
pip install django-haystack pip install jieba
使用jieba分词
1.cd到site-packages内的haystack包,创建并编辑ChineseAnalyzer.py文件
# (注意:pip安装的是django-haystack,但是实际包的文件夹名字为haystack) cd /usr/local/lib/python3.8/site-packages/haystack/backends/ # 创建并编辑ChineseAnalyzer.py文件 vim ChineseAnalyzer.py
2.修改ChineseAnalyzer.py文件内容
import jieba
from whoosh.analysis import Tokenizer, Token
class ChineseTokenizer(Tokenizer):
def __call__(self,
value,
positions=False,
chars=False,
keeporiginal=False,
removestops=True,
start_pos=0,
start_char=0,
mode='',
**kwargs):
t = Token(positions, chars, removestops=removestops, mode=mode,**kwargs)
seglist = jieba.cut(value, cut_all=True)
for w in seglist:
t.original = t.text = w
t.boost = 1.0
if positions:
t.pos = start_pos + value.find(w)
if chars:
t.startchar = start_char + value.find(w)
t.endchar = start_char + value.find(w) + len(w)
yield t
def ChineseAnalyzer():
return ChineseTokenizer()
3.替换分词器
cp whoosh_backend.py whoosh_cn_backend.py vim whoosh_cn_backend.py
# 导入ChineseAnalyzer,并将原有的StemmingAnalyser替换为ChineseAnalyzer from .ChineseAnalyzer import ChineseAnalyzer # from whoosh.analysis import StemmingAnalyzer
vim替换命令: %s/StemmingAnalyzer/ChineseAnalyzer/g
4.修改setting.py文件
# 全文搜索框架配置
HAYSTACK_CONNECTIONS = {
'default': {
# 使用whoosh引擎
# 'ENGINE': 'haystack.backends.whoosh_backend.WhooshEngine',
# 使用jieba分词
'ENGINE': 'haystack.backends.whoosh_cn_backend.WhooshEngine',
# 索引文件路径
'PATH': os.path.join(BASE_DIR, 'whoosh_index'),
},
}
5.重新建立索引
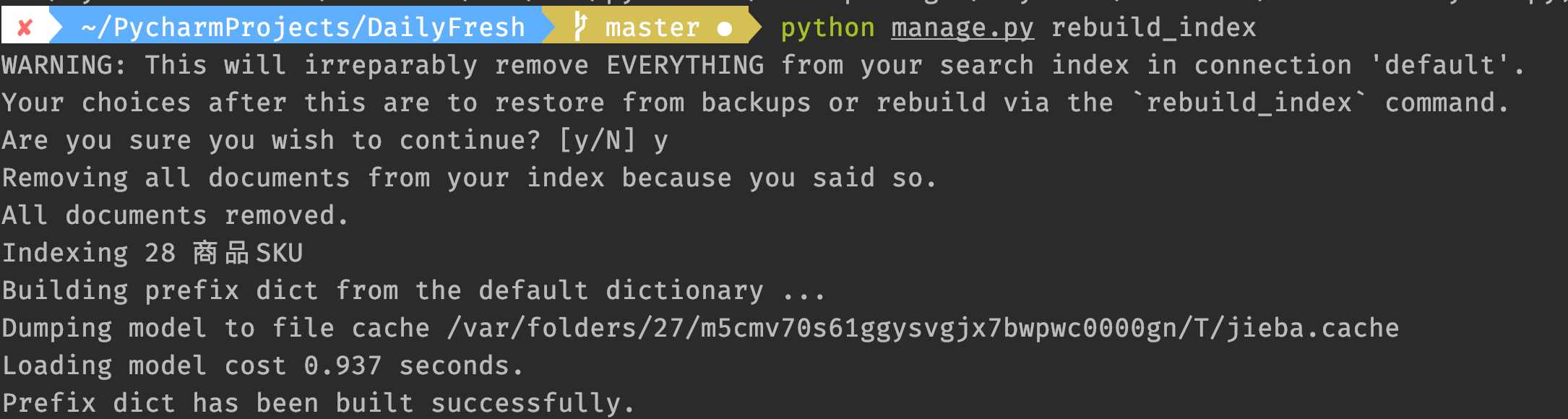
python manage.py rebuild_index
可以看到,已经使用了jieba分词。

到此这篇关于Django实现whoosh搜索引擎使用jieba分词的文章就介绍到这了,
推荐阅读